
Manipulation Paper Reading 02
因为这个文章和上一个是继承关系所以代号是02。
在开始正文之前我先做一个反思。在很长很长一段时间阅读论文的过程中,我总是很盲目地去关注这个论文使用了什么方法以及这个方法的细节是什么。却无意识地走进了一个巨大的时间陷阱,就是这个方法是否可靠。现在很多论文包括被CCFA接受了的论文,其实都可能参考意义有限或者就是在赶时间水论文,没有提出真正有实用性的方法,或者说“平庸的论文提出方法,优秀的论文提出问题”,绝大多数工作都没有提出新的问题,而是在旧问题旧方法上玩着排列组合的游戏。很多的talking和讲座,也是insight少宣传多。一个方法如果本身就价值有很局限,去把那个方法的细节研究清楚完全就是在浪费自己宝贵的时间和热情。
要首先关注这个方法到底针对什么任务在做,做到什么程度,是真的可靠还是无意义的sota。然后再把自己的精力献给真正可靠的优质工作。这是一个 learning how to learn 的问题。我曾天真地以为自己有了系统的Note管理以及足够的热情和不错的工具辅助算一个勉强懂学习的人,现在发现这种理解实在是肤浅。大胆地去做把自己做的不好的地方向别人展现出来,并且及时记录下自己的问题。
以上是我所有的闲话,回到正题上来。在 Post Training RL Paper Reading01 我过分关注了很多不可靠的方法,除了VLAC和RL100这种绝对优秀的工作,比较可靠的工作只有 PLD,SELF-IMPROVING EMBODIED FOUNDATION MODELS,WMPO。其中 PLD 是最可靠的,SELF-IMPROVING EMBODIED FOUNDATION MODELS真机装配实验没有做完整, WMPO的世界模型不实用而且可能有过拟合的问题,动作表征也做的不好。
我意识到RL只是方法导向,真正重要的主题是如何在真机上进行精细的操作(如插拔,如装配,甚至很多任务可以设计的更复杂),在操作方面,具身智能会迎来一段野蛮生长的时期,我开始第二轮调研。
每一个论文会有 一个星级评价(结尾) 和 一句个人评价(开头)。
⭐ 看了一次不会再想看二次的论文
⭐⭐ 不错的论文,看完学习上有所收获
⭐⭐⭐ 很好的论文,看完研究上有所启发
⭐⭐⭐⭐ 震撼的论文,可以是一段时间的 talking 话题
⭐⭐⭐⭐⭐ 无与伦比空前绝后的论文,可以写进教科书
思考一个问题
如果有一下两个工作可以实现,你希望实现哪个工作:
-
可以做到任何任务100%的成功率,但是仅限于拟合单任务。
-
可以通用学习所有任务,但是每个任务成功率80%左右。(而且是要求是基于学习的方法)
1 对 工业很有实用性,2 是 更符合理想。
1 是 注定可以被走通的,2 才是在真正的要解决的问题。或者2 究竟可不可能成为现实 本身就是一个问题。
Learning a Thousand Tasks in a Day
我的评价: 1000个任务确实很牛!但是如果是开环且不依赖scaling law,这个工作如何被借鉴或者扩展呢?我认为开环检索只是为了极致数据效率的极致做法,但是参考意义不大。这个工作可靠的观点就是把学习分解为“对齐”和“交互”两个阶段,这个范式可以被迁移!
关键信息
任务类型: 极其多样化,包括刚体(开箱 、插面包 )、可形变体(折短裤 、插书包 )和精细操作(铲煎饼 、拉拉链 )。这些任务是非常有说服力的灵巧操作(dexterous manipulation)。
- 受控实验: 包含 10 种微技能和 70 个物体。
- 大规模实验: 包含 1,000 个不同任务、402 个物体和 31 种宏观技能。
MT3 (Ret-Ret) 碾压 SOTA (在低数据区),主要思想是 “分解” 和 “检索” 。真正实现了“实用”的机器人教学,挑战了“Scaling Law”的范式,有可解释性与可靠性。
但是这个方法为了实现极致的数据效率,放弃了闭环反馈是一个开环,牺牲了鲁棒性,无法满足“反应式控制 (reactive control)”的需求。
Method
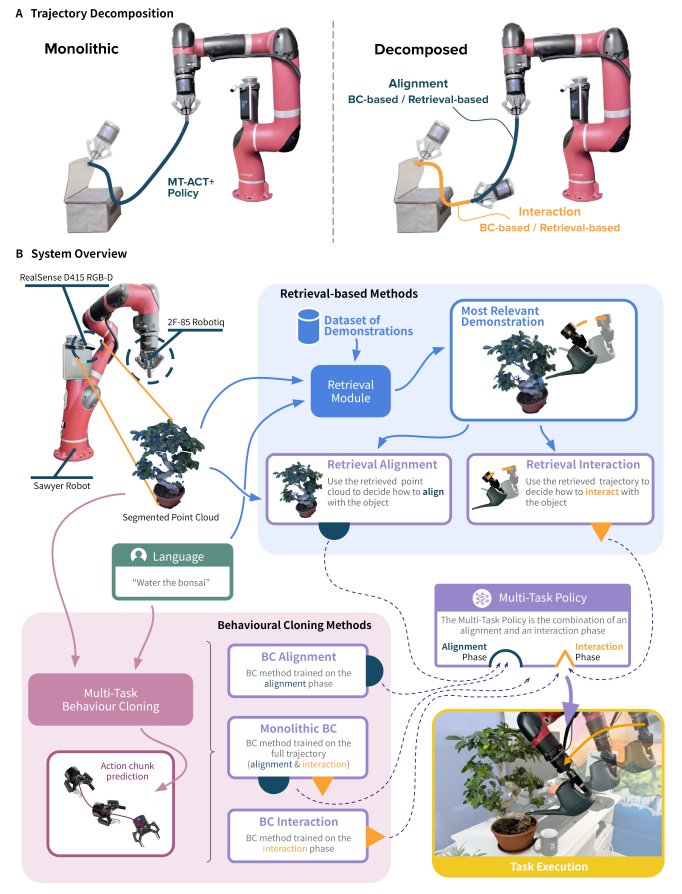
“分解” :
- 对齐 (Alignment) 阶段: 任务是把机器人的末端执行器(或抓着的物体)移动到适合开始交互的那个起始姿态。在这个阶段,只关心最终姿态是否正确,不关心路径(比如,机器人可以绕个大圈,只要最后停对了地方就行)。
- 交互 (Interaction) 阶段: 任务是从那个对齐好的姿态开始,执行真正精确的操控动作。在这个阶段,路径和动作必须非常精确(比如插插头,动作必须笔直稳定)。
将一个复杂问题(学习完整轨迹)拆分为两个更简单的子问题(学习对齐 + 学习交互),就能带来性能上的提升,尤其是在演示数据有限的情况下。
“检索” :
- BC-BC,BC-Ret,Ret-BC和Ret-Ret对比实验,一个单独的、一体化的 (monolithic) 神经网络(命名为 MT-ACT+)也参与对比证明分解的有效性(最后实验结果是分解 > 一体化)。
我的评分: ⭐⭐
Robot Learning a Physical World Model
我的评价: 它的这个视频生成模型不实用!它的World Modeling可以借鉴。
关键信息
流程是 Image -> Video Generation -> World Modeling -> Robot Manipulation。实验是真实世界机器人的pouring和Insertion。方法的关键是 “物理世界建模”提升操控鲁棒性。
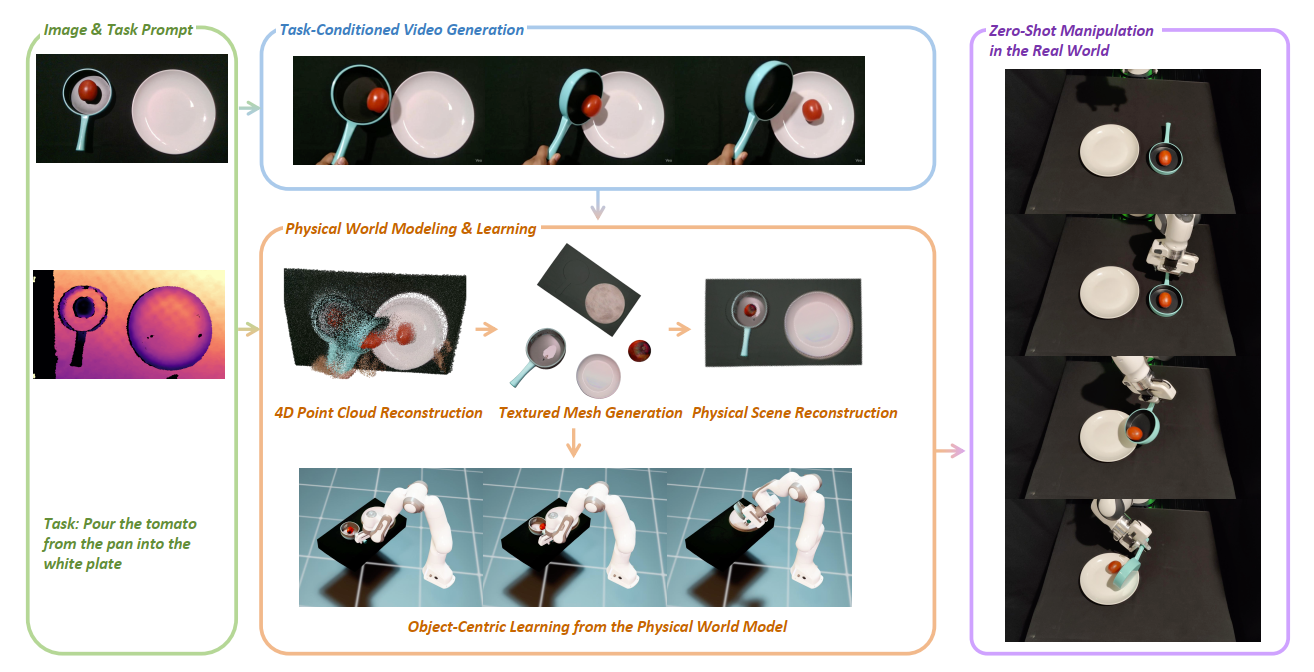
在Physical World Modeling & Learning创建的物理仿真器中,使用残差强化学习 (Residual RL) 训练一个机器人策略,让它学会如何物理可行地复现这个“物体轨迹“。
我的评分: ⭐⭐
RT-Trajectory
我的评价:和NoTVLA思路一类的经典工作。和Post RL没有关系,单纯作为补充了解一下。
关键信息
Pick from Chair,Move within Drawer等难度稍微大一点的pick and place任务。
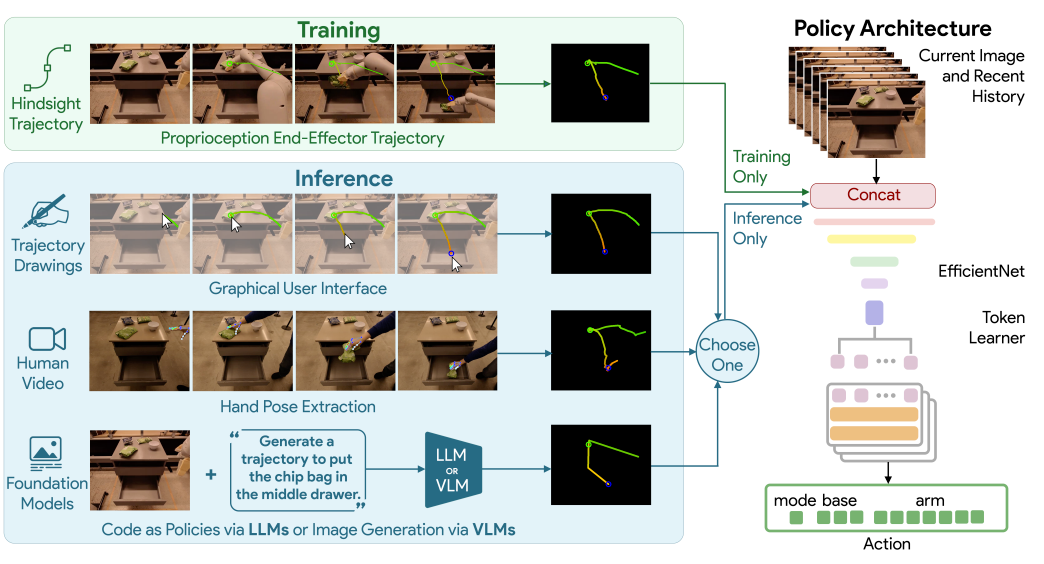
该方法依赖于一个固定的、标定好的相机来将3D轨迹投影为2.5D草图。
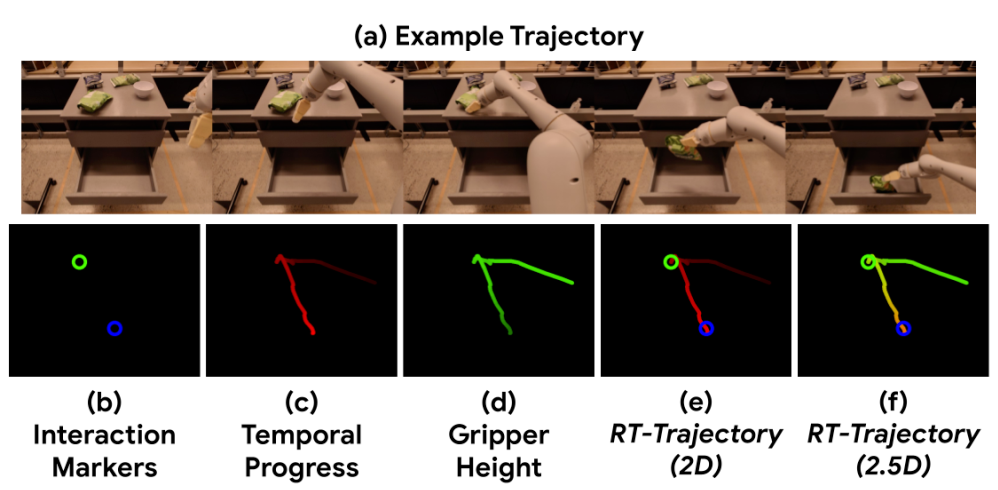
上图从左到右是 2D路径,时间进度,高度 (Z轴)和交互。最后的f是结合的结果。“2.5D”轨迹图像随后与当前的相机RGB图像在特征维度上进行拼接 (Concatenate)。
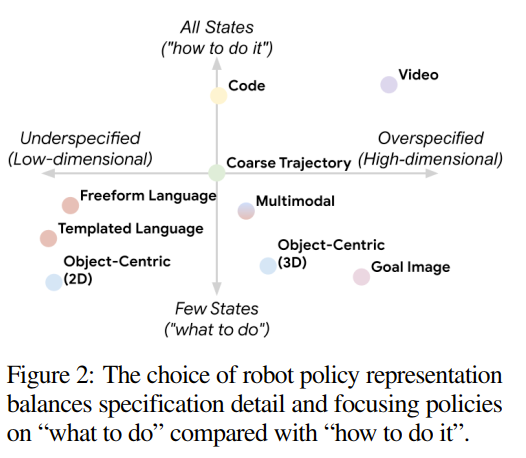
我的评分: ⭐⭐⭐
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
我的评价: 虽然存在“Reward Hacking”(机器人学会了欺骗分类器。例如,摆出一个看似成功了的姿势,而不是真正完成任务)和 为了 实时性能和训练效率 冻结VLA主干网络 的 问题。但是真机实验比较有说服力,而且范式不错。
关键信息
全真机实验,这组任务选得很好:它不仅包括简单的“拾取-放置”(如拿香蕉、拿勺子),还包括了真正有难度的 “富含接触”的精细操作,如 “插轮子”(Insert Wheel) 和 “挂中国结”(Hang Chinese Knot) 。这些任务对策略的精度和鲁棒性要求极高。
解决预训练的VLA模型(如Octo)在“落地”到特定真实世界任务时面临的数据困境。通过强化学习(RL)安全、高效地将模型微调到高水平。
-
纯RL(如HIL-SERL )在真实世界中样本效率极低 ,因此他们设计了ConRFT这种“离线-在线”的混合范式。
-
不同于SFT+HIL (e.g., HG-DAgger)允许人类在SFT过程中进行干预,不一致的人类干预(噪声)反而会干扰SFT的学习过程。
Method
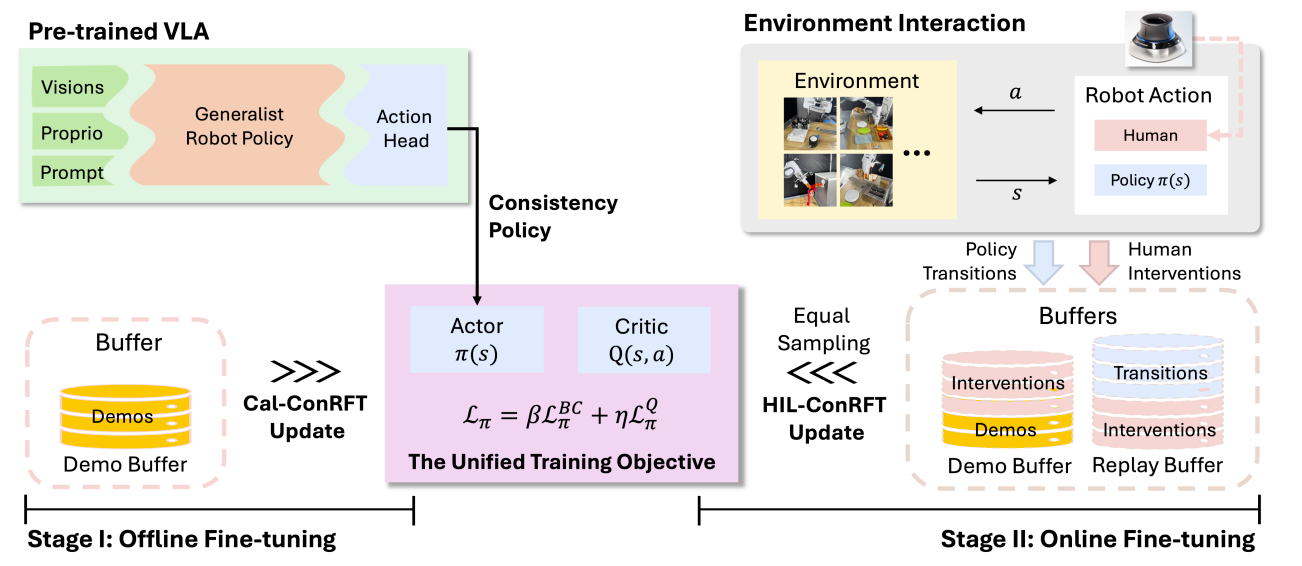
-
一个统一的、基于一致性(Consistency)的训练目标 (BC+Q-Learning)
- 选择Cal-QL是为了是希望Q函数对 “分布外”(OOD) 的动作保持鲁棒。
- 引入BC是为了弥补Cal-QL在小数据集上的缺陷。
-
在离线阶段(Cal-ConRFT):从小数据集中高效初始化。通过结合BC和Cal-QL(一种离线RL算法),从极少量(20-30个)不完美的演示中,学习到一个稳定且鲁棒的策略和价值函数。
- 使用一致性策略(Consistency Policy) 作为VLA的动作头。有助于利用演示数据中不一致和次优的部分,轻量高效。
-
在在线阶段(HIL-ConRFT):保留统一的训练目标(实现快速适应),并结合人因在环(HIL) 的干预 ,该方法能安全地探索环境(人类防止灾难性失败),同时高效地利用新数据(包括人类的纠正数据) 来快速优化策略
-
保留离线阶段的演示缓冲区(Demo Buffer D),创建一个新的重放缓冲区(Replay Buffer R)来存储在线交互产生的新数据。
-
对称采样(Symmetric Sampling) :在训练时,从 D 和 R 中等比例采样数据。
-
需人类干预!
- 确保安全
- 如果陷入局部最优/无法恢复人类干预加速学习。
-
可拓展方向
自适应的模块化微调:
-
系统可以先用一个“诊断”模块判断当前场景是否在预训练的分布内。
- 如果在分布内,就只微调动作头(如ConRFT),追求最高实时性能。
- 如果在分布外(即检测到“未见场景”),则开始在线微调VLA主干的表征能力,以适应这个新情况。
-
更dense的奖励机制或者更细粒度的奖励标注。
我的评分:⭐⭐⭐
ForceVLA
我的评价: 我曾经参与的工作…
关键信息
加入力反馈加了个MoE,真机实验做的好,精细操作能力很强,而且是通用模型。
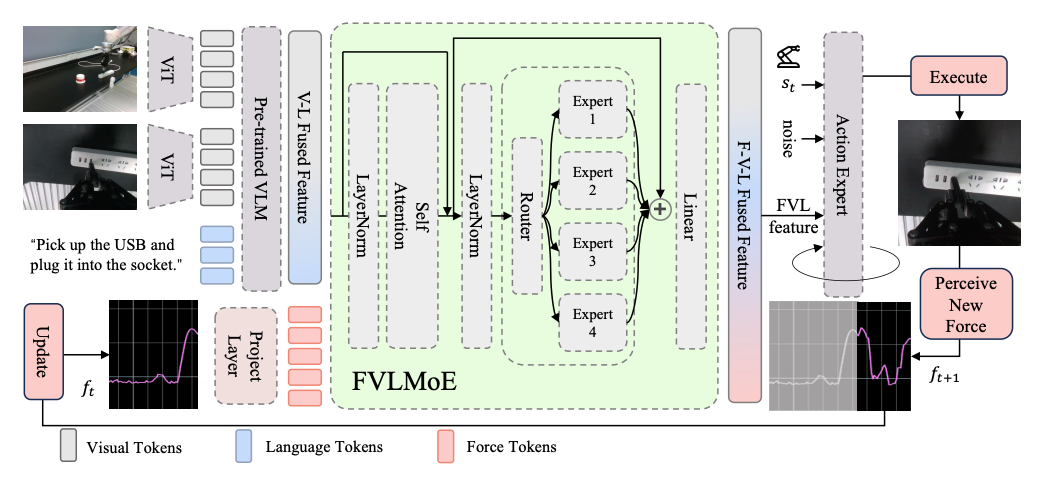

我的评分:⭐⭐⭐
Human-in-the-loop Online Rejection Sampling for Robotic Manipulation
它来自清华大学和腾讯Robotics X实验室 ,发表于2025年10月 ,非常新。
我的评价: 虽然真机实验结果很漂亮但是人类干预太多了!而且还是 单任务的 (single-task) ,但是真机任务难度确实说服力很强。
关键信息
三个具有挑战性的真实世界“接触密集型” (contact-rich) 操控任务。

传统RL试图 学习 一个价值网络(Q-function)来 估计 动作的好坏 。Hi-ORS的核心洞见是:彻底放弃不稳定的Q-network!
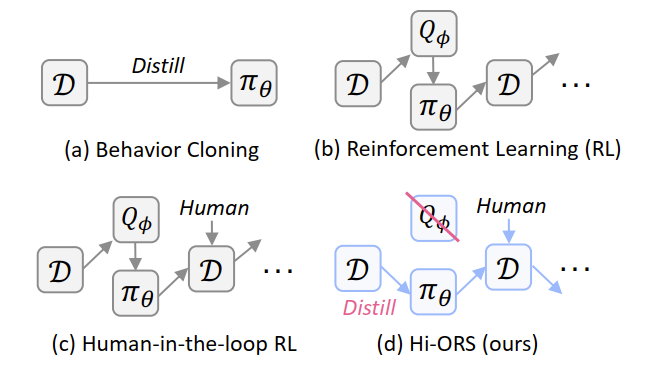
Method
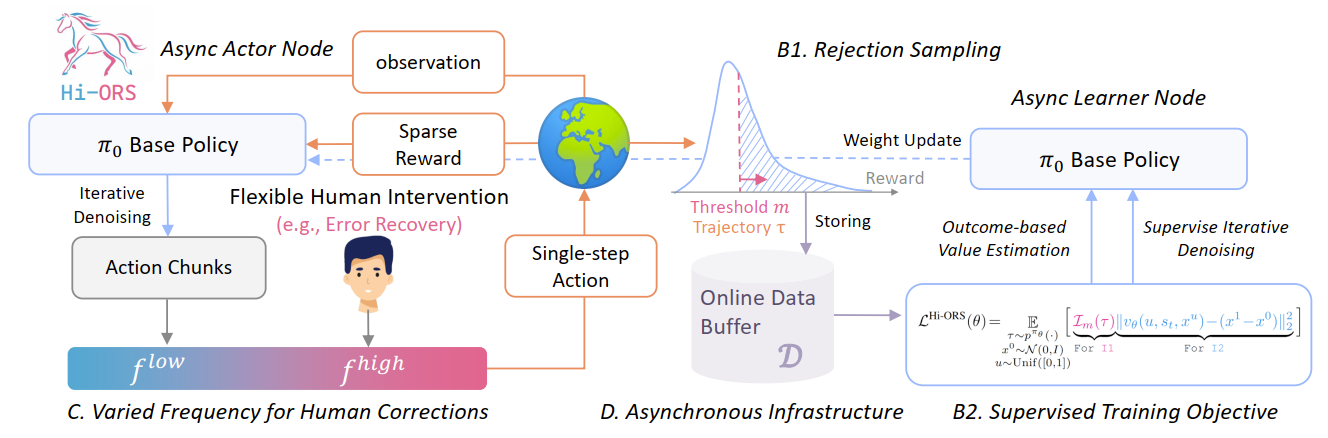
-
输入 (Input): 一个预训练好的基础VLA策略 () ,以及来自真实世界的环境观测(如多视角图像、语言指令)。
-
模块 A: 异步Actor节点 (在机器人上执行) :
- 基础策略 () 在真实机器人上执行任务(如“插入保湿霜”) 。
- 同时,人类操作员(如使用Meta Quest 3 )可以随时介入,进行灵活的人工干预(如纠正机器人的抓取姿态)。
-
模块 B: 在线数据缓冲 (D) :
- 收集完整的执行轨迹(包括策略自主执行和人工干预的部分) 。
- 为每条轨迹附加一个稀疏的任务奖励(通常是二元的:成功/失败)。
-
模块 C: 拒绝采样 (B1. Rejection Sampling) :
- (这是最关键的组件) 系统设置一个奖励阈值
m。 - 遍历数据缓冲(D),过滤所有轨迹:总奖励 (即成功)的轨迹被保留;总奖励 (即失败)的轨迹被丢弃 。
- (这是最关键的组件) 系统设置一个奖励阈值
-
模块 D: 异步Learner节点 (在GPU上训练) :
- 仅使用上一步中被接受的“成功轨迹”数据 。
- 使用监督训练目标 (B2. Supervised Training Objective) 来更新(“Distill”)基础策略 () 的权重 。
-
输出 (Output): 一个经过微调、更稳健、且学会了错误恢复的VLA策略 。
我的评分:⭐
ALOHA Unleashed
我的评价:证明在低成本硬件,无需力矩传感器,使用非专家收集数据,也能实现灵巧操作SOTA性能。不过策略是单任务的,还是在过拟合!网络架构倒是可以参考一下。印证了我开头说的拟合单任务100%成功率这条路一定是可以走通的说法。
关键信息
“大规模数据 + 强表达力模型”这一“简单配方”在解决被视为机器人“圣杯”级难题(如系鞋带)时的惊人效果。
挂衬衫 (Shirt Hanging),系鞋带 (Shoelace Tying),更换机器人手指 (Robot Finger Replace),齿轮插入 (Gear Insertion)和厨房物品堆叠 (Random Kitchen Stack)。
面对大规模、多样化的真实数据,使用强表达能力的生成模型(如Diffusion)是必须的。(实验结果:Diffusion 远优于 ACT)。


我得评分:⭐⭐
SPIDER: Scalable Physics-Informed Dexterous Retargeting
我的评价: 好久没看到这么Solid的工作,看到这个论文就好像呼吸了一口新鲜的空气!
关键信息
实现规模、效率和物理真实性的统一。它与 SOTA 最大的不同在于,它不使用 RL ,而是采用了一种基于采样的优化 (Sampling-based Optimization) ,这使得它比 RL 快一个数量级 (10x) ,同时又因为它在物理模拟器中进行采样,保证了轨迹的动态可行性(优于 IK)。
大规模、跨形态的验证,并开源了数据生成管线。
真实机器人任务(非常有说服力) :SPIDER 生成的轨迹(无需额外训练)直接在真实的 Franka 臂 + Allegro 手上执行 。成功完成了 旋转灯泡、弹吉他、拔充电器 等需要高精度、多指协调的灵巧操作任务 。
跨形态,跨任务域,跨数据集和跨数据质量。
-
核心洞见 (Key Insight): SPIDER 的核心思想是解耦。
- 让人类演示提供高层指导(任务结构和目标)。
- 让大规模的物理采样(在模拟器中)来提炼轨迹,确保其动态可行性和接触正确性。
-
关键技术 (Virtual Contact Guidance): 为了解决“接触信息缺失”的挑战,SPIDER 引入了“虚拟接触引导”机制。这相当于在优化初期,施加一个虚拟力,将机器人的手“粘”到期望的接触点上,以确保它学会正确的接触模式。这个力会随着优化逐渐放松。
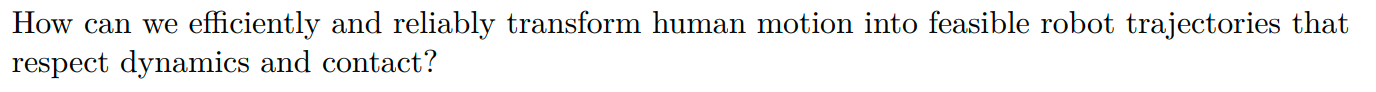
Method
由于任务的物理接触特性(非凸且非连续),我们不能用梯度,所以选择了一种“基于采样的优化”;并且为了平衡“探索”(找到接触)和“利用”(稳定接触),我们在采样时使用了一个动态“退火”的搜索半径,让它从大范围搜索逐渐变为精细调整。

- 论文举例 (Stir Stick): 比如,在“搅拌”任务中,机器人可以用“拇指和食指”(人类的方式)捏住棒子,也可以用“食指和中指”捏住。
- 失败原因:两种方式都能完成任务(物体运动相似),但后者不符合人类演示的意图。由于优化问题的“非凸性”,一个标准的采样优化器很可能会收敛到任何一个可行的解,导致它学会“非人类”的、不自然的接触模式
- 不能简单地添加一个“软奖励 (soft reward)” 。 因为如果期望的接触模式本身就很难被采样到(比如在一个很窄的“山谷”里),那么即使有奖励,优化器也可能找不到它。
-
SPIDER 采用了一种更强硬的策略,它“显式地扩大了(期望解的)吸引盆 (enlarges the basin of attraction)”。
-
实现机制:
- “粘合” (Sticking): 在优化的初始阶段,它在“期望的”接触点(如机器人的指尖和物体的握柄)之间施加一个**“虚拟约束”**。这就像用胶水把它们暂时“粘”在一起,强迫优化器朝这个方向探索。
- “课程” (Curriculum): 这个“粘合”约束不是永久的。它会以**“课程学习”的方式“逐渐放松 (gradually relaxed)”**。

(Equation 4): 这种约束的核心是保持 “相对位置 (relative position)” 。它不关心机器人手指或物体的绝对坐标,只关心“机器人指尖”相对于“物体握柄”的相对位置是否与人类演示中的一致。这大大降低了采样复杂度。
另外一个细节是加了个“接触过滤器” :如果一个接触的持续时间太短(小于 ),或者接触点漂移得太厉害(大于 ),它就被归类为“不稳定”。确保只有可靠的、有意义的接触点才会用来“引导”优化过程,从而防止了噪声数据对最终结果的干扰。

人形机器人学习残差。
我的评分: ⭐⭐⭐⭐
EO-1
我的评价:真机实验非常的具有说服力,Discussion(Sec4.9)十分清晰地说明了他们的方法为什么是有效的。
关键信息
针对 “交错式推理与交互” (Interleaved Reasoning and Interaction) 的能力。
精细灵巧操作 (Dexterous): “叠衣服”, “做三明治”, “烤牛排” 。在这些任务上,EO-1 (81.0% avg) 显著优于 (67.0%) 和 GR00T (68.0%)。
推理控制 (Reasoning Control): “视觉重排” 和 “井字棋” 。在井字棋上,EO-1 (76.0%) 吊打 (24.0%) 和 GR00T (36.0%) 。这雄辩地证明了其统一架构在“实时推理-行动循环”上的绝对优势。
这项工作为“交错式推理-行动”这一核心难题提供了第一个真正意义上SOTA的、端到端的解决方案(模型+数据+训练)。它指明了摆脱“Act-at-the-End”僵化范式的可行路径。
挑战了分层架构的必要性: 在机器人领域,长期以来“高层规划(LLM)”和“底层控制(Policy)”都是分离的。EO-1 证明了将二者统一在单一模型中是可行的,且性能更强 ,因为它消除了分层带来的通信瓶颈和误差累积。
Method
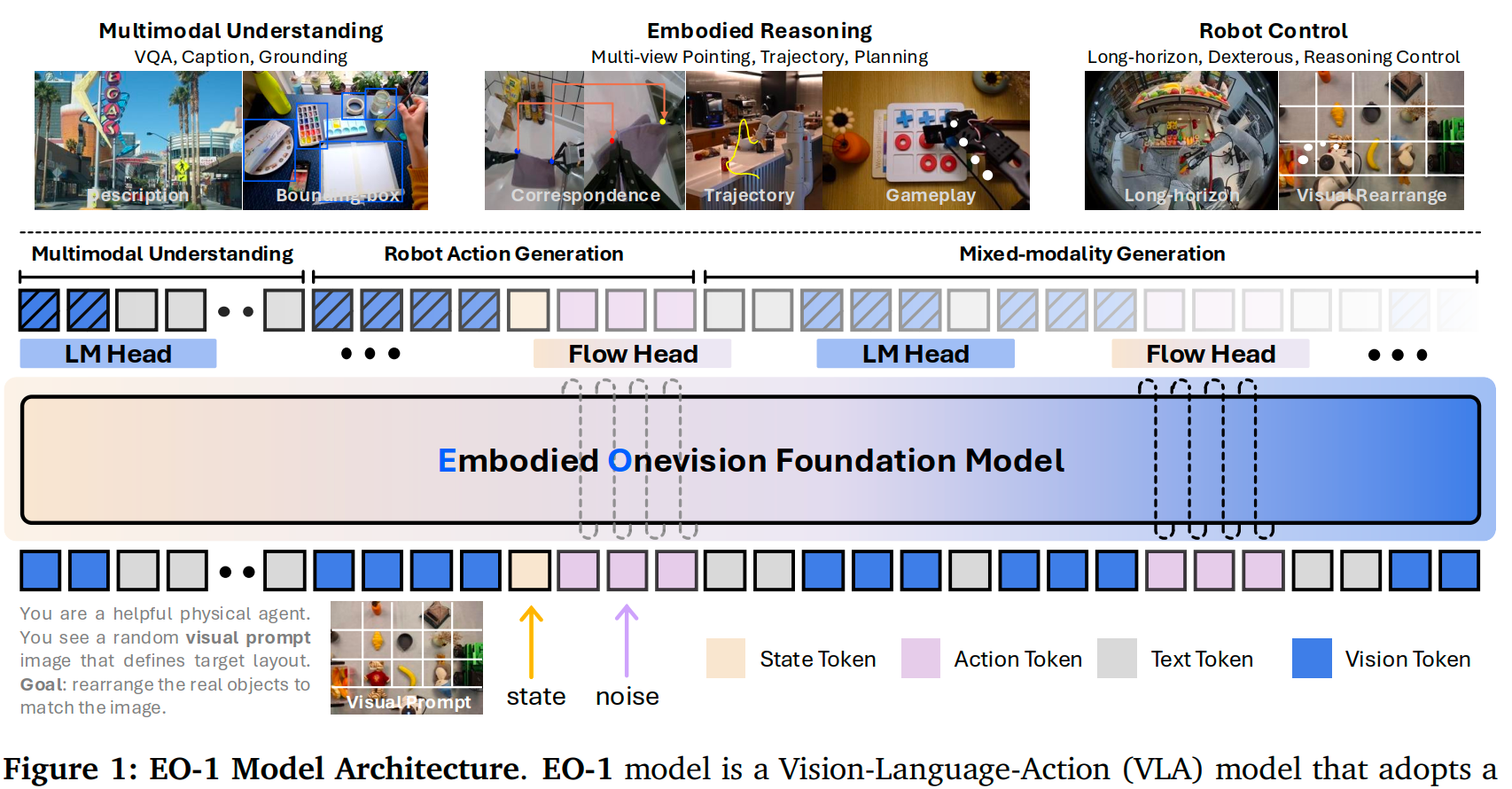
Figure1: 4种token的混合解码架构。
-
输入 (Input): 模型接收一个交错的Token序列 。这个序列包含了:
- Vision Token (视觉): 图像块(Image Patches)。
- Text Token (文本): 任务指令或中间的推理QA。
- State Token (状态): 机器人本体状态(如关节角度)。
- Noisy Action Token (带噪动作): 用于Flow Matching训练目标的带噪动作 。
-
核心模块 (Core Module): 一个单一的、共享参数的解码器Transformer(“Embodied Onevision Foundation Model”,基于Qwen2.5-VL初始化) 。它使用Causal Attention(因果注意力)处理整个多模态序列 。
-
输出 (Output) - 混合解码: Transformer的输出会根据下一个需要生成的Token类型,被送入两个不同的头部 :
- 如果需要“推理”: 序列被送入 LM Head(一个标准的Logits预测头),通过自回归方式采样生成离散的文本Token(例如,生成"下一步是拿起杯子") 。
- 如果需要“行动”: 序列被送入 Flow Head(一个MLP),通过流匹配方式降噪并预测出一个连续的动作向量(例如,生成
[0.1, -0.2, ...]的关节动作)。
最关键的设计选择:
- 混合解码 (Hybrid Decoding): 这就是EO-1的核心。它没有像其他模型那样把动作也“Token化”(离散化),而是保留了文本的离散性(适合逻辑推理)和动作的连续性(适合精确控制),并在同一个模型中实现。
- 交错数据格式 (Interleaved Data): 模型的强大能力严重依赖 EO-Data1.5M 这种
[V-T-A-V-T-A...]的数据格式 。 - 交错纠正采样 (Interleaved Rectifying Sampling): 一种特殊的训练策略(见图2 )。因为在训练时,一个
action既是Flow Matching的clean target,又是后续text_QA的condition。这个策略能确保模型在训练时正确处理这种因果依赖 。


Discussion
它试图厘清 (isolate) EO-1模型的成功到底归功于:
- (i) 创新的混合解码架构:即“自回归(AR) + 连续流匹配(Flow)”的统一解码器。
- (ii) 大规模的交错式V-T-A数据:即 EO-Data1.5M 这种
[V-T-A-V-T-A...]的数据格式。
做了“四方”对比实验去验证:
-
发现一:架构 - 混合解码 (AR+Flow) 完胜 纯AR
- 对比:
EO-1 (base) vs.EO-1 (fast)。
- 对比:
-
发现二:数据 - “对齐”的交错数据至关重要
- **对比:**
EO-1 (interleaved) vs.EO-1 (base)。
- **对比:**
-
发现三:“通用”的多模态数据有害!
- 对比:
EO-1 (llava) vs.EO-1 (base) 或EO-1 (interleaved)。 - 与具身控制任务未对齐的通用图文数据(如LLaVA),会“将模型偏向于语言先验,从而削弱其物理落地能力 (physical grounding)”。
- 对比:
EO-1的卓越性能并非来自单一的创新,而是来自架构和数据的协同作用。
它的成功归功于一个统一的架构(混合解码)和为其量身定制的数据(对齐的、交错的V-T-A数据)的完美结合。这种“联合建模” (joint modeling) 不仅加强了多模态理解和运动控制之间的时间对齐,也确保了模型在开放世界和分布外场景中的稳定和高性能。
我的评分:⭐⭐⭐⭐





