
RL Post Training Paper Reading01
许华哲老师的 RL100[1] 和 Skild AI (一家致力于为机器人构建 Foundation Models 的“独角兽企业”)的 LocoFormer [2]是我近期关注到的热门工作,《The Bitter Lesson》[3]总结道:AI 研究 70 年来的最大教训是,那些充分利用算力(Leverage Computation)的通用方法(如搜索和学习) ,最终总是以压倒性优势胜过那些试图利用人类知识的方法。LocoFormer 让我们感受到迈向通用控制模型的趋势,相较于 RL100 在单任务上取得封顶的成功率,把这种能力扩展到多任务也是必要的。最近相关 Post Training RL 工作具有这方面的潜力,尤其是一些改进的 offline RL 算法,具有很高的数据效率,也采取一些方法去缓解训练不稳定的问题。所以针对这些工作以及相关工作我展开调研。
PS: RL for flow matching的工作本次调研过滤掉了,RLinf-VLA/ReinFlow/这个几个工作质量挺高的,这类工作往往针对flow matching机制去做手脚,如果之后需要参考这类工作再细看。
每一个论文会有 一个星级评价(结尾) 和 一句个人评价(开头)。
⭐ 看了一次不会再想看二次的论文
⭐⭐ 不错的论文,看完学习上有所收获
⭐⭐⭐ 很好的论文,看完研究上有所启发
⭐⭐⭐⭐ 震撼的论文,可以是一段时间的 talking 话题
⭐⭐⭐⭐⭐ 无与伦比空前绝后的论文,可以写进教科书
Perceiver Actor Critic
ICML2024 Offline Reinforcement Learning
我的评价: 来自DeepMind的工作,很有insight。
关键信息
我们展示了离线 Actor-Critic (AC) 强化学习 (RL) 可以扩展到大型模型(例如 Transformer),并遵循与监督学习 (SL) 相似的缩放定律 。
我们引入了一个基于 Perceiver 的 Actor-Critic 模型,并阐明了使离线 RL 能够与自注意力和交叉注意力模块协同工作的关键模型特性 。总的来说,我们发现:i) 简单的离线 AC 算法是从当前主流的 BC 范式逐渐过渡的自然选择;ii) 通过离线 RL,可以从次优演示或自生成数据中学习到能够同时掌握多个领域(包括真实机器人任务)的多任务策略。
本文提出的Offline RL方法可以从 混合质量数据中学习(包含很多次优的数据) 中学习,摆脱对纯专家数据的依赖。
核心贡献有:
- 首次证明Offline RL的Scaling Laws:离线 Actor-Critic 算法在扩展到大型 Transformer 模型(高达 1B 参数)时,同样遵循类似 Chinchilla 的缩放定律 。研究发现 RL 目标(PAC)的性能扩展性优于纯 BC 目标 。这意味着随着计算预算的增加,使用 RL 获得的回报比使用 BC 更多.
- 提出高效的 Perceiver-Actor-Critic (PAC) 架构
- 在次优数据上远超 BC 的实证
- 平滑插值与自我改进循环:该算法提供了一个超参数 ,允许在 BC 和 RL 之间进行平滑、稳定的插值 。 这在工程上极为有用:可以先用 (纯 BC)“安全”地预训练,然后再减小 (转向 RL)进行策略提升 。更重要的是,这套框架支持自我改进 (self-improvement) :在真实机器人上部署模型,收集(不完美的)新数据,扔回数据集,用离线 RL 进行迭代优化,最终将真实机器人的成功率从 69.8% 提升至 93.2% 。
PS:
- Chinchilla缩放定律揭示了在训练大型语言模型时[4],模型参数量与数据集大小之间的最佳配比,以实现计算效率的最大化。
Method
它没有使用计算昂贵且复杂的offline RL正则化方法,而是在总损失中添加BC损失(),这个损失像“缰绳”一样防止策略去追逐“被过高估计的”虚假高分动作。
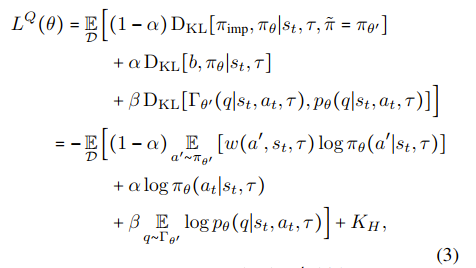
- 当 时,BC。
- 当 时,RL。
- 或者调参到最优:模型在模仿的同时,被允许“稍微”优化一下策略。
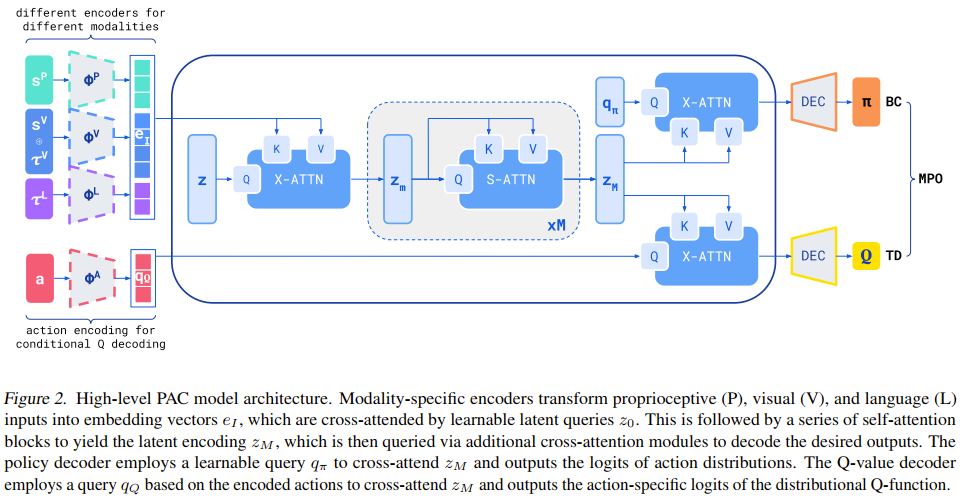
这个架构要解决的核心矛盾是:机器人需要处理海量的多模态输入,但又要在极短的时间内(例如 1/20 秒)做出决策。标准的 Transformer 架构做不到,因为它的计算复杂度是 (N=序列长度,N很大。)
Perceiver 是一个信息压缩模块,数千个输入 token ,使用交叉注意力,让这 32 个 向量去“读取”和“压缩”那数千个 token。计算复杂度从 降低到 ()。输出一个包含所有“状态”信息的压缩向量。然后Actor Critic如何解码向量在Figure2中画的很清晰。
实验&&Insight
关键洞见 1:当数据质量高时,RL 的优势不明显。
关键洞见 2:当数据质量差时,BC 彻底失败,而 RL 展现巨大优势。

真机实验,“自我改进”循环 (The Self-Improvement Loop)。
-
实验流程 (Table 3) :
- 起点 (Iteration a-PAC) :部署 69.8% 成功的
a-PAC模型。 - 第1轮 (RLFT #1) :让机器人在真实世界中运行,收集 110k 条新的、由它自己产生的数据。将这些数据加回原数据集,然后用 Offline RL 算法(PAC)重新训练。成功率飙升至 84.7% 。
- 第2/3轮 (RLFT #2, #3) :重复这个过程。再次收集数据(+75k, +11k),再次训练。
- 终点:成功率最终达到了 93.2% ,实现了“精通” (mastery > 90%) 的目标。
- 起点 (Iteration a-PAC) :部署 69.8% 成功的
-
核心洞见:
- 这证明了 PAC 框架解锁了 BC 范式完全不具备的能力:自我提升。
Discussion
Insight 1:最大的“阿喀琉斯之踵”——奖励 (Reward)
Insight 2:最大的“失望”——没有真正的泛化 (No Transfer)
“画饼”: 作者提出了三个非常激动人心的(但很遥远)的未来方向:
- 做更大:扩展到数十亿参数。
- 加 VLM:和视觉语言模型(如 RT-2 那样)结合。
- “登月计划” :用 RL 的 Actor-Critic 范式,去替代 Transformer 的“生成式预训练”范式,甚至用在语言模型上。这是一个非常、非常激进的想法,暗示着 RL 可能是通往 AGI 的另一条路。
(这里讨论时引用了些工作,我回头有空看看)
Broader Impact
Insight 1:安全的第一道防线——“离线” (Offline is Safe)
Insight 2:RL 反而是实现“对齐”的钥匙 (RL is Easier to Align)
- 这为什么更好? 因为这个“奖励函数”就成了一个 “价值对齐的抓手” 。我们可以把“人类偏好” (Human Preferences) 编码到这个奖励函数里,从而“塑造” AI 的行为。
- 一句话总结:作者认为,BC 这种“没有意图”的AI反而更难对齐,而 RL 这种“有奖励意图”的AI,反而更容易让我们把它的意图“对齐”到人类的价值观上。
我的评分:⭐⭐⭐
WMPO
最近arxiv新论文,来自字节,on policy RL。
我的评价: 基于Sora级别的视频生成模型,有钱公司可以玩。而且我不看好离散化动作表示,最近工作[5]已经揭示了Co-Training和Latent Action是更promising的方向。当然在附录中作者也承认了他们认为离散动作是局限性未来会做flow matching,应该是赶着发paper。比较work的小trick还挺多。
关键信息
我们引入了基于世界模型的策略优化(WMPO),这是一个在不与真实环境交互的情况下实现On-Policy(同策略)VLA RL的原则性框架 。与广泛使用的潜空间(latent)世界模型不同,WMPO专注于基于像素的预测,将“想象”的轨迹与在网络规模图像上预训练的VLA特征对齐 。至关重要的是,WMPO使策略能够执行On-Policy的GRPO算法,这比常用的Off-Policy(异策略)方法提供更强的性能 。在模拟和真实机器人设置上的大量实验表明,WMPO(i)显著提高了样本效率,(ii)实现了更强的整体性能,(iii)涌现出如自我纠正等行为,以及(iv)展示了鲁棒的泛化和终身学习能力 。
Related Work:
- 对比 (1) 直接RL (如VLA-RL , SimpleVLA-RL ): 这些工作尝试在模拟器中或真实世界中直接应用RL(如GRPO, PPO) 。WMPO的不同之处在于完全不与真实环境交互来进行RL更新 ,而是全部在“想象”中完成,从而实现数量级上的样本效率提升。
- 对比 (2) 潜空间世界模型 (Latent WM, 如Dreamer , Hafner系列 ): 这是经典的Model-Based RL范式,它们在一个人为压缩的、抽象的“潜空间”中学习动力学 。WMPO认为,这与VLA模型(如OpenVLA)存在根本性的“错配” (mismatch) 。因为VLA是在真实像素(Web规模图像)上预训练的 ,强行让它去理解抽象的“潜空间”会损失其强大的视觉理解能力
实现鲁棒的世界模型与策略对齐(能模拟失败) 为了让RL有效(即能从失败中学习),世界模型不仅要能模拟成功,更要能忠实地模拟失败。WMPO通过关键的 “策略行为对齐” (Policy Behavior Alignment) 技术实现这一点:它使用VLA策略自己在真实环境中收集的(包含成功和失败的)少量数据 来微调世界模型,使其“见识”过失败并能准确预测失败的动态 。
Method
还引入了噪声帧条件(noisy frame conditioning)和帧级动作控制(frame-level action control)技术,以克服长时程视频预测中的视觉失真和动作-帧未对齐问题。
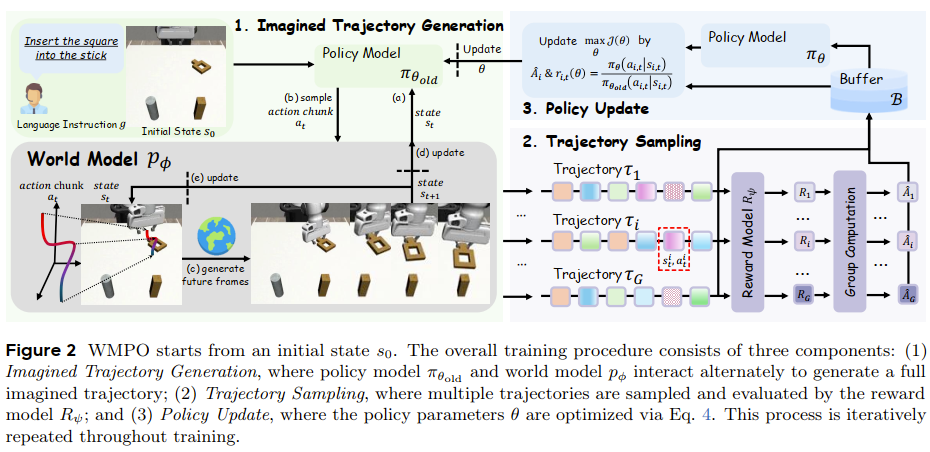
生成式世界模型
问题:自回归,误差会像滚雪球一样累积。
- 长时程 - 噪声帧条件 (Noisy-frame conditioning):这是一个巧妙的“鲁棒性”训练技巧。在训练时,他们故意“弄脏”输入模型作为条件的帧。这相当于告诉模型:“即使你之前的预测(作为你现在的输入)有点不完美,你也必须给我生成一个好的未来”。这使得模型对自己的小错误具有了“容错性”,从而能稳定生成数百帧。
- 精准控制 - F-level action control:他们通过修改 AdaLN 模块,将动作信号 强力注入到 Transformer 的每一帧。这确保了模型生成的特定帧与输入的特定动作紧密“对齐”,解决了“动作-帧未对齐”的问题。
问题:RL 的精髓是“从失败中学习”。但如果世界模型只用 OXE 或专家演示(全是成功案例)来训练,它将无法“想象”出失败。当 VLA 策略在“想象”中执行了一个错误动作时,这个“天真”的世界模型会不知所措,它要么产生一个错误的成功幻想,要么干脆崩溃。
- 解决方案:用 VLA 策略自己在真实环境中收集的(包含大量失败的)数据,去微调世界模型。
奖励模型
-
正样本 (Positive) :只有成功轨迹的最后那个片段 。
-
负样本 (Negative) :
- 所有失败轨迹中的任意片段。
- 以及,成功轨迹中除最后片段之外的所有中间片段 。
-
Implication (影响) :这个定义非常严格。它在告诉模型:“只有任务完成的那个确切时刻才是值得奖励的(正样本),其他所有时刻,哪怕是在通往成功的正确道路上,都算作未成功(负样本)”。这本质上是在训练一个 “任务完成检测器” 。
-
模型架构:VideoMAE [39] + 线性头。这是一个强大的视频理解骨干网络,非常适合用来从一个视频片段(轨迹片段)中分类出结果。
-
损失函数:二元交叉熵损失。奖励 。
-
给予奖励方式是滑动窗口+“或”逻辑。
RL
动态采样 (Dynamic Sampling)
- 问题:GRPO 这类算法需要通过“对比”来学习(即这条轨迹比平均水平好还是差)。如果采样的一组(Group)轨迹全是成功的(奖励全为1)或全是失败的(奖励全为0),那么“方差”为0,算法就学不到任何东西(梯度消失)。
- 解决方案:如果一个组“全好”或“全坏”,就直接扔掉 (discarded) ,重新采样,直到采到“有成功也有失败”的混合组。
实验&&Insight
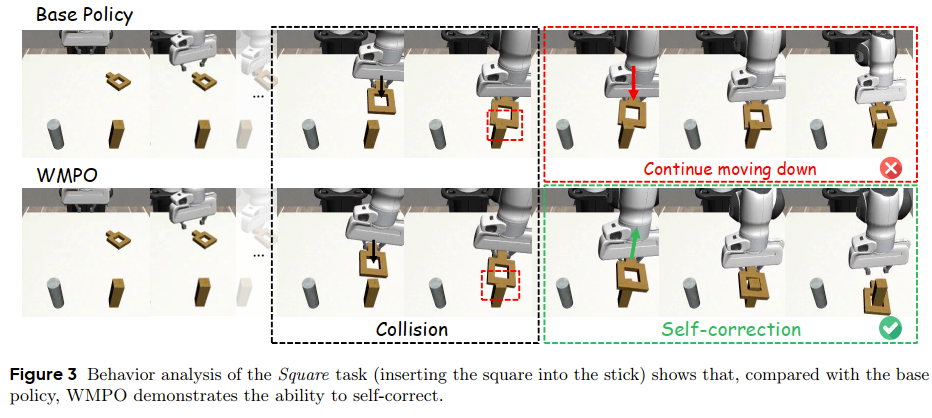
涌现出自我纠正的能力。
有关LifeLong Study的观点:
WMPO 是一个可迭代的框架。策略 可以收集新的数据 新数据用来微调世界模型 和奖励模型 更好的 和 用来训练出更好的策略 形成一个良性循环。
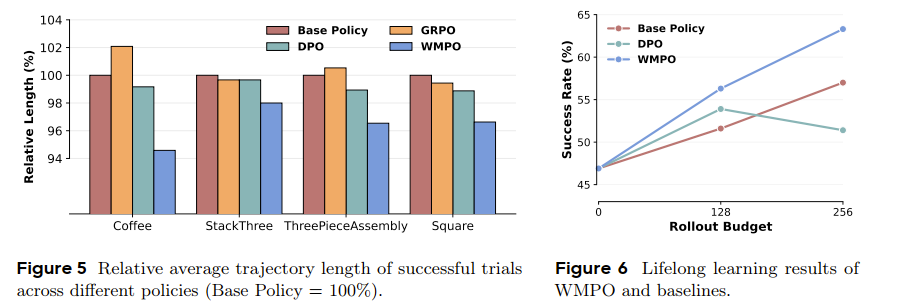
我的评分: ⭐⭐
SELF-IMPROVING EMBODIED FOUNDATION MODELS
2025NIPS Poster 来自DeepMind Online RL
我的评价:巧妙的奖励函数设计!
关键信息
- 相较于“Code-as-Rewards”等工作:这些工作尝试用LLM生成代码来设计奖励函数,但仍面临奖励工程困难、需要环境检测接口等问题。本论文的动机是完全摆脱人工奖励工程,通过让模型自己预测“任务进展”(即“剩余步骤数”),创造了一个数据驱动、自我生成的奖励信号。
- 核心动机:让机器人拥有 “自我迭代、持续进化” 的能力。
Method
即使有了完美的reward shaping,在真实世界中测量奖励也需要大量的工程努力。通过学习数据驱动的奖励函数来克服这一障碍,这些函数也从底层基础模型的网络规模预训练中继承了鲁棒性和泛化能力。我们提出的后训练框架由两个阶段组成:1) 监督微调(SFT) ,在此阶段我们使用行为克隆以及“剩余步数”(steps-to-go)预测目标来微调具身基础模型(EFMs);以及 2) 自我提升(在线强化学习) ,在此阶段,EFMs通过优化自我预测的奖励来自主练习下游任务并快速进步。
SFT双学习目标:
- 正常action loss
- 预测
t_done - t_now(巧妙且无需额外的label)

-
两个模型,一个学生一个老师:算法最关键的一个细节是,它使用了两个来自阶段1的模型。
- 一个模型作为策略(Policy) ,是“学生”,它的参数会被RL算法不断更新。
- 另一个模型被冻结(frozen) ,作为奖励和成功检测器,是“老师”。
-
为什么要冻结“老师”? 这是为了保证学习的稳定性。如果“老师”的标准也在不停变化,那“学生”就很难学好了(所谓的“追逐移动的目标”)。冻结的奖励模型提供了一个稳定的评估标准。
-
学习循环:整个过程是一个大的循环:收集数据 → 更新策略 → 清空数据 → 收集新数据…
- 更新策略:使用REINFORCE算法,根据回报
R_t来调整“学生”策略。回报高的动作,其被选择的概率会增加;回报低的则会降低。
- 更新策略:使用REINFORCE算法,根据回报

图中是剩余步数的概率质量函数,当策略成功质量函数收敛且集中在0,当策略即将失败质量函数发散。
Insight
-
当把 代入奖励函数 后,就变成了 。
-
当把这个奖励函数代入蒙特卡洛回报 的计算公式时,会发生一个“伸缩求和”(Telescoping Sum)现象,中间项大部分都抵消了,最终结果简化为一个简洁的形式。
-
这个形式的末尾,天然地出现了一个 项。在策略梯度算法(如REINFORCE)中,从回报中减去一个只依赖于状态的函数(称为基线(Baseline) ),是一种标准的方差缩减技术。它能极大地稳定训练过程,而不会改变策略更新的期望方向。
-
作者的奖励函数设计,自动地、免费地就产生了这个非常有用的基线项,从而降低了REINFORCE算法的方差,提高了训练效率和稳定性。这是该方法设计的另一个优雅之处。
-
主要局限性:
- 整个过程仍需一个初始的模仿学习数据集来“冷启动”。
- 过拟合风险:过度优化自生成奖励可能导致性能下降,需要设计更好的停止策略或正则化方法。
- RL算法的效率:为了稳定性,论文使用了相对简单的On-policy RL算法(REINFORCE),这在数据重用方面效率不高。未来采用更先进的Off-policy算法可能会进一步提升样本效率。
我的评分: ⭐⭐
ReinBoT
MiLAB 王东林老师
我的评价:不同寻常的RL(指不依靠Value Iteration)。
关键信息
训练数据质量的可变性常常限制VLA的性能 。另一方面,离线强化学习 (Offline RL) 擅长从混合质量的数据中学习鲁棒的策略模型 。
ReinboT (Reinforced robot GPT) ,这是一种新颖的端到端VLA模型,它融合了最大化累积奖励的RL原则 。ReinboT通过预测密集回报 (dense returns) 来捕捉操作任务的细微差别,从而实现对数据质量分布的更深理解 。这种密集回报预测能力使机器人能够生成更鲁棒的、以最大化未来收益为导向的决策动作 。大量实验表明,ReinboT在CALVIN混合质量数据集上达到了SOTA性能,并在真实世界任务中表现出卓越的少样本学习和分布外 (OOD) 泛化能力 。
Method
Dense Reward
离线强化学习 (Offline RL) 的核心是评估 (evaluate) 数据质量。但机器人任务的奖励通常是稀疏的(比如任务最后成功了才+1),这导致RL无法学习(即信用分配难题)。
在此做出了一个清晰的权衡:牺牲“奖励设计”的通用性,来换取“VLA策略模型”的通用性。精心设计的密集奖励(尤其是 和 )是高度任务相关的。它被设计用来奖励“机械臂桌面操作”。
- (平滑度) :这是纯粹的物理/控制层面的奖励。它不关心任务目标,只关心动作是否“舒服”(低阶导数小)。这在CAD中(例如运动规划、曲线/曲面光顺)是完全共通的。
- (子目标) :这是几何/感知层面的奖励。它计算的是当前状态与目标状态在多模态特征空间(本体感知、图像MSE、SSIM、ORB特征)中的“距离”。
- 和 (进展/完成) :这是纯粹的语义/逻辑层面的奖励。
端到端强化VLA

设计了一个 “回报-条件化” (Return-Conditioned) 的动作解码器。通过我们提出的密集奖励,我们可以获得长时序视觉-语言操作任务的ReturnToGo (RTG) 。
- 传统VLA模型是
(V, L) -> A。 - Decision Transformer (DT) 是
(V, L, RTG_target) -> A,但RTG是外部给定的。 - ReinboT的精妙之处在于它自己预测RTG,并且不是用它作为最终输出,而是将其作为中间特征来调节 (Condition) 动作的生成。
- 关键在 Equation (13) :动作解码器 的输入是 和 的拼接。(action输出这里是最关键的)

- 这在多模态融合中是一种非常高级的 “门控/调节”机制。 (来自RTG Decoder的隐藏特征) 扮演了一个 “高层规划” 的角色,它告诉动作解码器:“我们现在的目标是达到一个非常高的分数”。而 (来自骨干网络) 扮演了 “当前状态” 的角色。这个架构迫使“低层控制”(动作解码器)在生成动作时,必须服从“高层规划”(RTG预测)的指导。
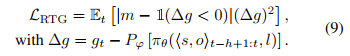
- 它使用的是分位数回归 (Expectile Regression) 损失。通过设置超参数 (在论文后续实验中,他们选了 ),这个损失函数变得不对称:它对“预测值低于真值”的惩罚(权重为 )远大于对“预测值高于真值”的惩罚(权重为 )。
- 这种不对称性迫使模型为了最小化损失,必须去拟合RTG分布的“高端” (即第90百分位数),而不是均值。这就从数学上实现了从“模仿平均”到“模仿最优” 的转变。
解决DT的“部署难题”,解决Reinformer的“效率难题”。
在部署友好(无需手动RTG)和高效率(单次推理)的前提下,成功地将Offline RL的优化能力注入到了VLA模型中。
- ReinboT 的妙处:它根本没有使用任何贝尔曼方程或TD损失。它的 (公式9)本质上仍然是一个监督学习的回归损失!
- 它实现RL的方式是“曲线救国”的:它不通过价值迭代去计算最优策略,而是通过序列建模去预测最优回报,再把这个预测作为条件来生成动作。
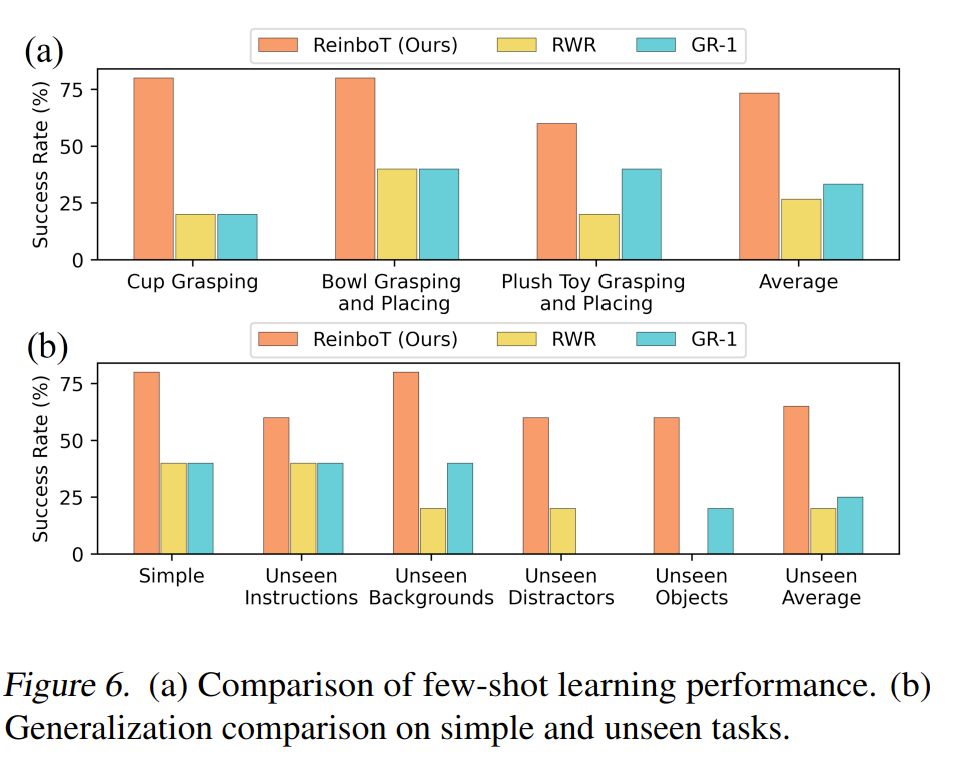
真实世界的少样本和OOD性能,比较有说服力。
我的评分: ⭐⭐
SELF-IMPROVING VISION-LANGUAGE-ACTION MODELS WITH DATA GENERATION VIA RESIDUAL RL
NVIDIA和CMU的工作
我的评价:“能插内存和他基础Model做了off policy rl关系不大。两个小时的真机rl拟合单任务,不过他们这个intervention少很多”
关键信息
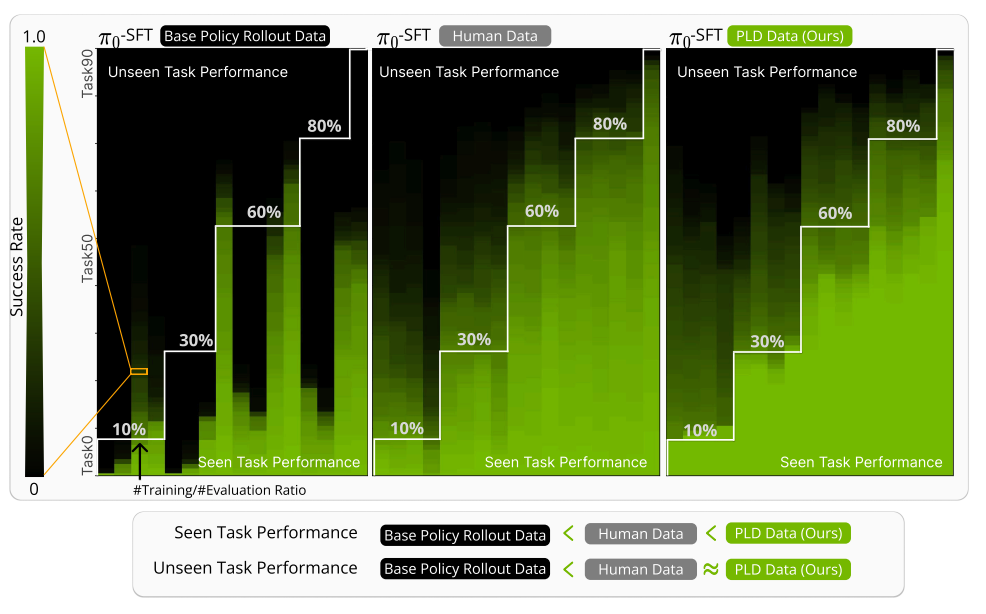
问题: 如何低成本、可扩展地提升大型VLA(机器人基础模型)的性能和泛化能力,摆脱对昂贵、低效且与模型实际部署分布不匹配的人类演示数据的持续依赖。
白线下面是Seen Task,白线上面是UnSeen Task。
PLD框架能够让机器人模型自主地生成数据,这些数据不仅在提升泛化能力方面和昂贵的人类专家数据一样好,而且在学习已见任务方面甚至超越了人类数据。

- RL专家数据质量很高,但缺乏多样性,并且与基础策略的行为差异很大。
- 而PLD数据与基础策略更好地对齐,并包含了多样的恢复行为。
Method
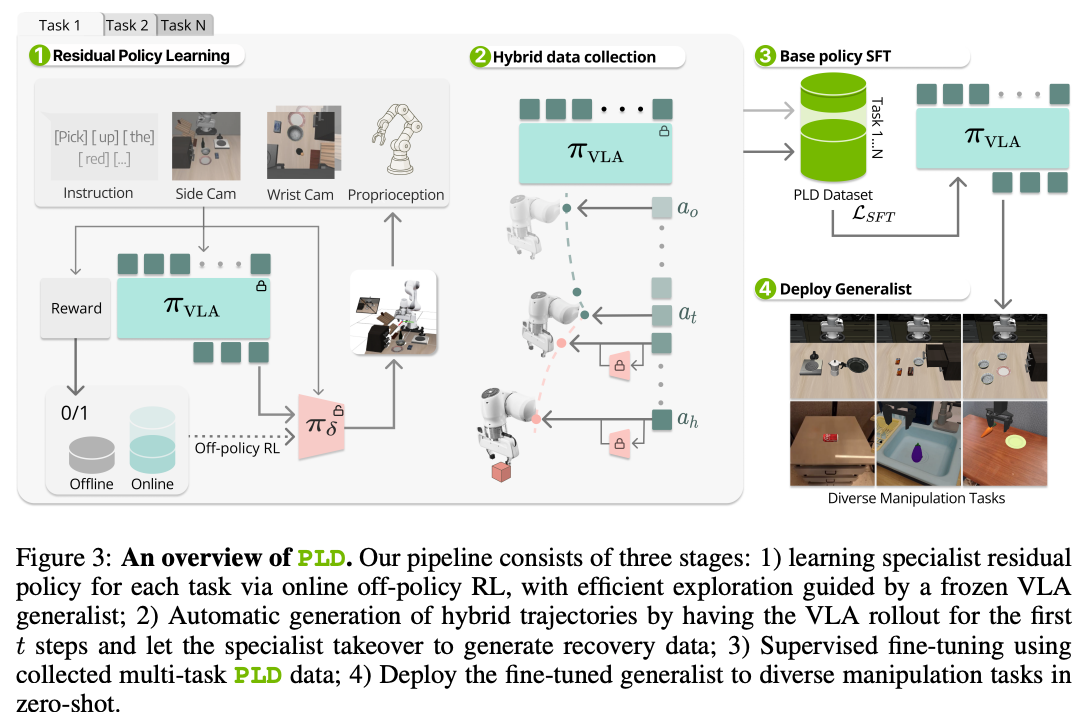
在Residual Policy Learning阶段做off Policy的残差强化学。
残差强化学习是基模的。这里的基模不是Model Based,是基础模型的意思。是一个预训练好的,有一定先验知识的基础策略。基础策略 输出 ,然后残差策略输出一个修正量 ,最后被执行的动作是 。
是冻结的,残差策略是被训练的。
Off-Policy算法存在训练不稳定的问题,这个作者提出了一个任何Off-Policy RL都能使用的Trick:
- 保守/"悲观"的Q函数初始化: Cal-QL 抑制探索OOD,没见过的action开始时Value是很低的。
- 受控的残差探索: 被人为限制在 之间
- 高质量离线数据预热: 收集成功轨迹填充 缓冲池
- 对称的经验回放: 50% 缓冲器 50% 缓冲池
自举法(BOOTSTRAPPING), 这个词源于一句英语谚语 “to pull oneself up by one’s own bootstraps”,字面意思是“通过拉自己的鞋带把自己提起来”,引申为 “自力更生”、“自我提升”。
在计算机和机器学习领域,它泛指任何利用系统自身当前的能力来生成新的数据或资源,从而反过来改进系统本身的过程。它是一个非常广泛和基础的思想。
- 系统自身包含一个不完美的“基础策略 (
πb)”。 - 系统利用这个
πb去生成有挑战性的“初始状态”。 - 这些状态被用来训练一个更强的“RL专家 (
πδ)”,从而改进了系统解决问题的能力。 - 最终,专家学到的新知识又通过蒸馏(Distillation)回馈给基础策略,完成了整个系统的自我提升闭环。
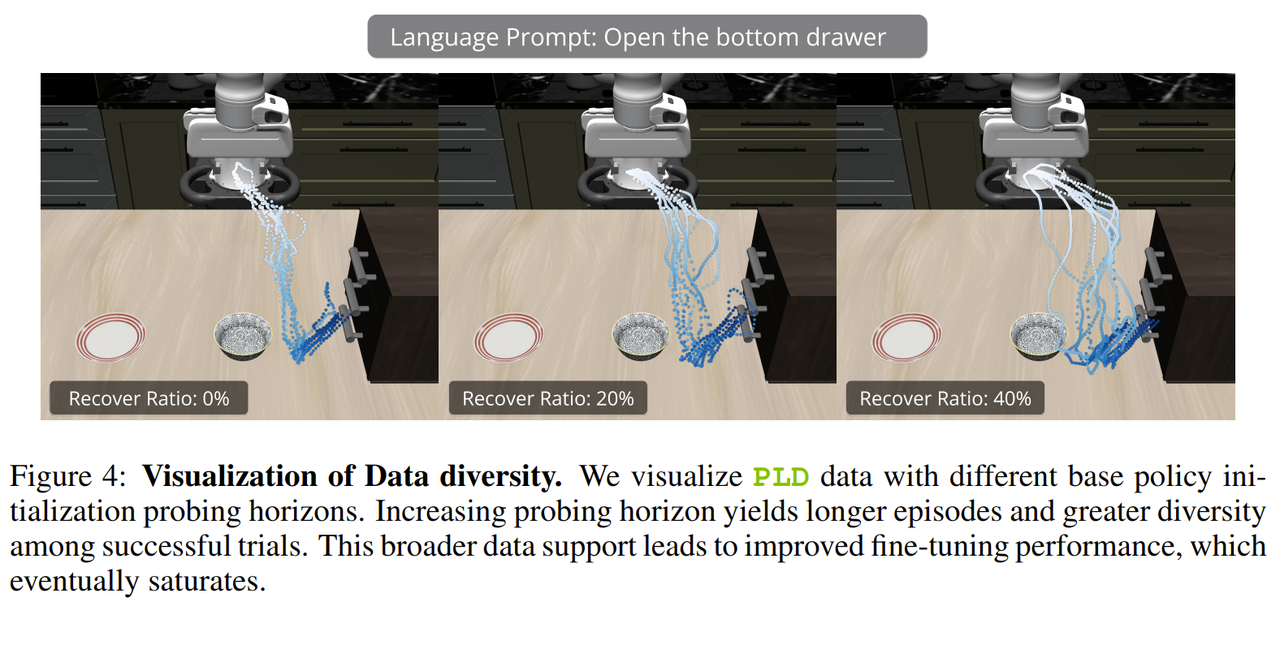
Figure4 展示探查范围越大,数据越丰富。
Insight
-
数据飞轮 (Data Flywheel) : 这里点明了PLD的潜力。PLD能发现模型的弱点 -> 创造包含解决方案的数据 -> 用新数据训练出更强的模型 -> 新模型又能发现更难的新弱点… 如此循环,形成一个自我强化的“数据飞轮”。
-
提供通用且实用的后训练范式:PLD框架与具体VLA模型架构解耦,使其可以作为一种通用“插件”来增强各种机器人基础模型,具有很强的实践价值和推广潜力。
-
任务专家的可扩展性:尽管RL训练是高效的,但当前框架仍需为每个(或每类)任务训练一个独立的残差专家策略。当任务数量扩展到成千上万时,这个过程仍可能成为瓶颈。
-
对奖励信号的依赖:该方法依赖于一个明确的、通常是稀疏的二元(成功/失败)奖励信号来训练RL专家。
我的评分: ⭐⭐⭐⭐
Q-Transformer
18/9/2023 这篇来自Google DeepMind的论文 Q-Transformer 。这是一篇在机器人学习领域非常有影响力的工作。
我的评价: 经典工作
关键信息
Transformer 的强大表示能力和可扩展性 && TD 学习的策略改进能力(传统RL的优势)&& 混合质量数据
在这个工作提出之前,Transformer 与 TD-learning 结合十分困难。Transformer 这种为“离散序列”设计的工具,与 RL 中 Q-learning 需要处理的“连续高维动作空间”及“TD更新”之间存在根本的鸿沟,强行结合会导致“维度灾难” 。因此,你需要一个像 Q-Transformer 这样的新方法论 ,而不是简单的模型替换。
通过将每个动作维度离散化,并将每个动作维度的Q值表示为单独的token,我们可以将有效的高容量序列建模技术应用于Q-learning 。我们提出了一些能够在线下RL训练中实现良好性能的设计决策,并表明Q-Transformer在一个大型、多样化的真实世界机器人操纵任务套件上优于先前的离线RL算法和模仿学习技术。
Method
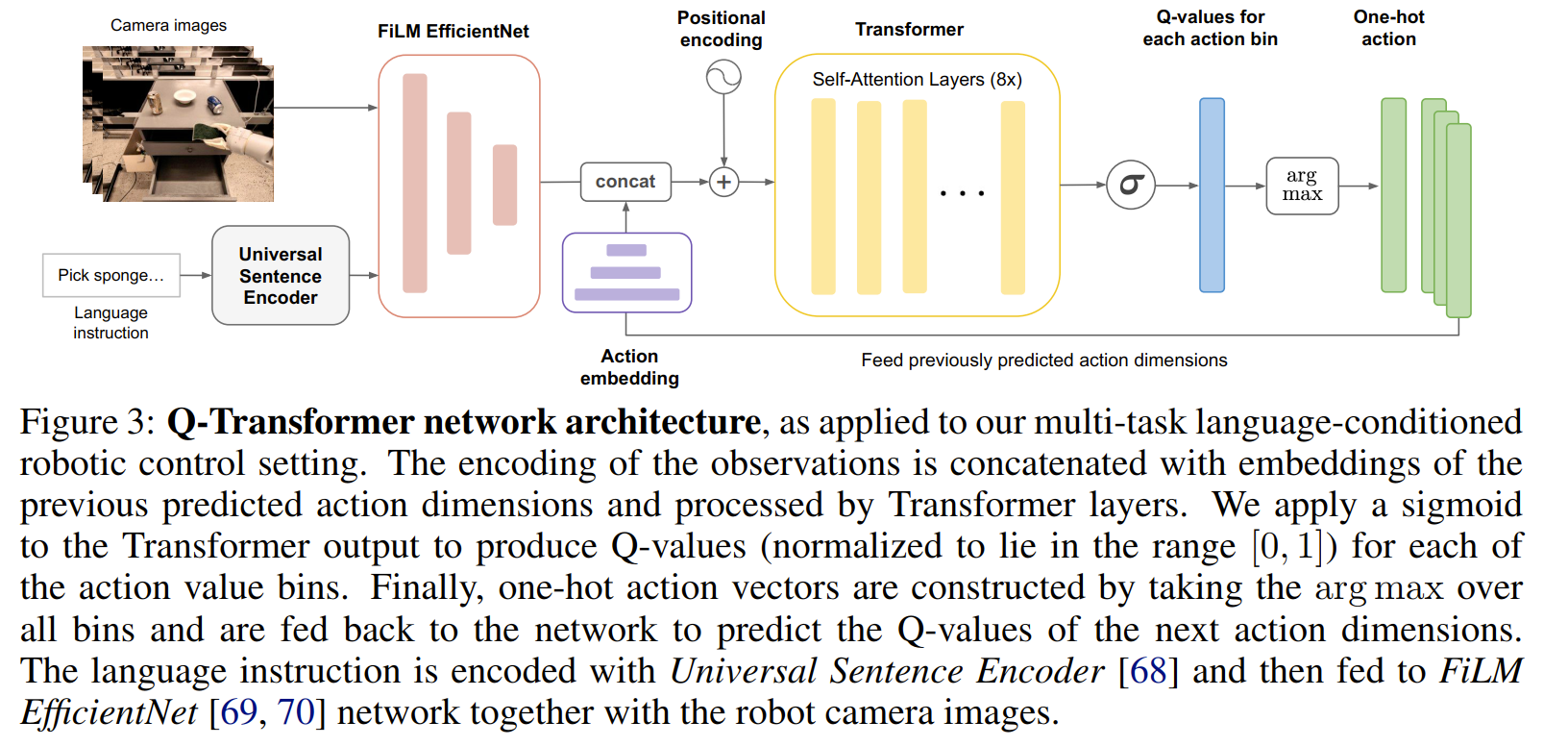
技术组件:
- 按维自回归 (Per-dimension autoregression) 。
- 保守Q值正则化 (训练时) 。
- Sigmoid Q值输出 。
(Q-Transformer):
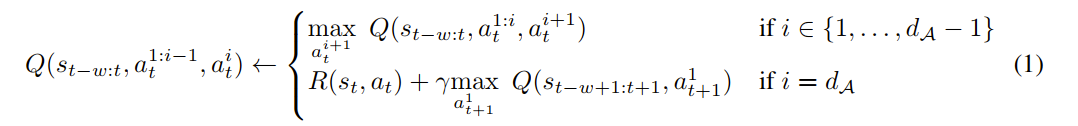
标准保守Q学习 (CQL) 的做法是:惩罚 (minimize) 那些数据集中未见过 (out-of-distribution) 动作的 Q 值 。但本文指出: 在机器人稀疏奖励(reward 只有 0 或 1)的设定下,标准 CQL 会把 Q 值推向负无穷 。这在逻辑上是错误的,因为机器人能得到的“最差”回报就是 0(失败),而不是负值。
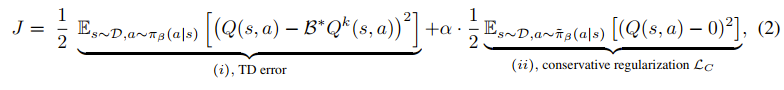
提升回报效率:
- 在计算“目标Q值”时,Q-Transformer 不再只用 TD 目标,而是取
- n-step 回报 来在“时间步”之间跳跃,设定 等于动作维度的数量 ,虽然这会引入一点“偏差”(bias),但实验证明 (Section 5.3) 这种偏差的影响很小,而训练速度的提升是巨大的。
局限性:
- 推理速度
- 均匀离散化: 采用了均匀的动作离散化 。这对于需要同时进行 “粗略”和“精细”控制的任务来说,可能不是最高效的。
我的评分:⭐⭐⭐
MoRE
ICRA2025 MiLAB
我的评价:针对四足机器任的优秀的工程实现,只是没有提出任何原创内容,限于各种已有方法拼接。
关键信息
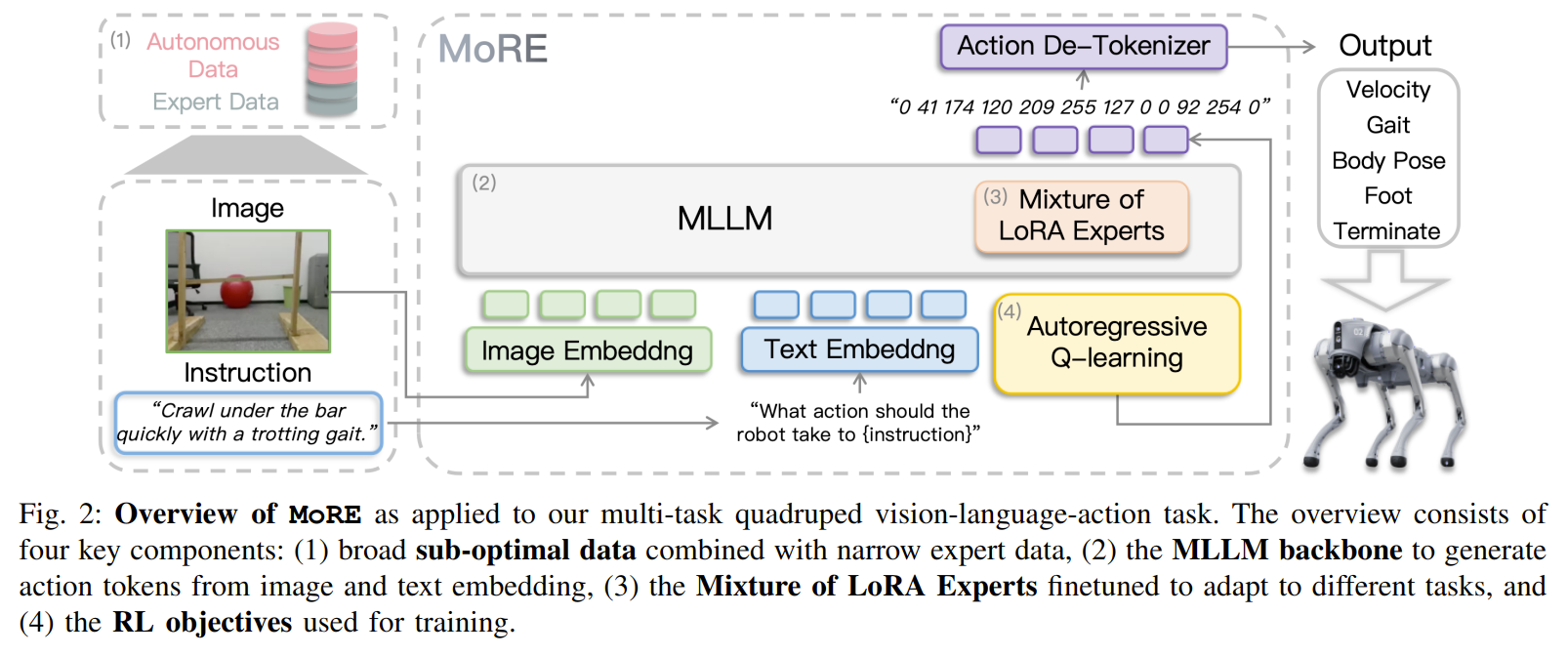
MLLM + MoLE + Q-Transformer
分析任务特性:
- 有限的关键点 (Limited critical points): 任务的成败只取决于少数几个关键状态。
- 大量的“足够好”动作 (Multi Good-enough Actions): 在大多数非关键状态下,存在大量“还行”的动作,偏离最优轨迹一点也无所谓。
- 他们因此论证,在这种“关键点少、容错率高”的场景下,模仿学习 (IL) 这种“死板”的方法就不如离线强化学习 (Offline RL) 。
- 首次将 MoE 架构成功应用于端到端 VLA 模型。
- 首次将 Q-Transformer 范式成功扩展到高维、多任务的 MLLM 上,实现了对混合质量数据的有效利用。
- 提供了 Insight:通过分析任务结构(关键点/足够好的动作),解释了为什么这个组合是有效且必要的。
我的评分: ⭐
GeRM
IROS2024 MiLAB
我的评价: 是MoRE的前继工作,思路趋同 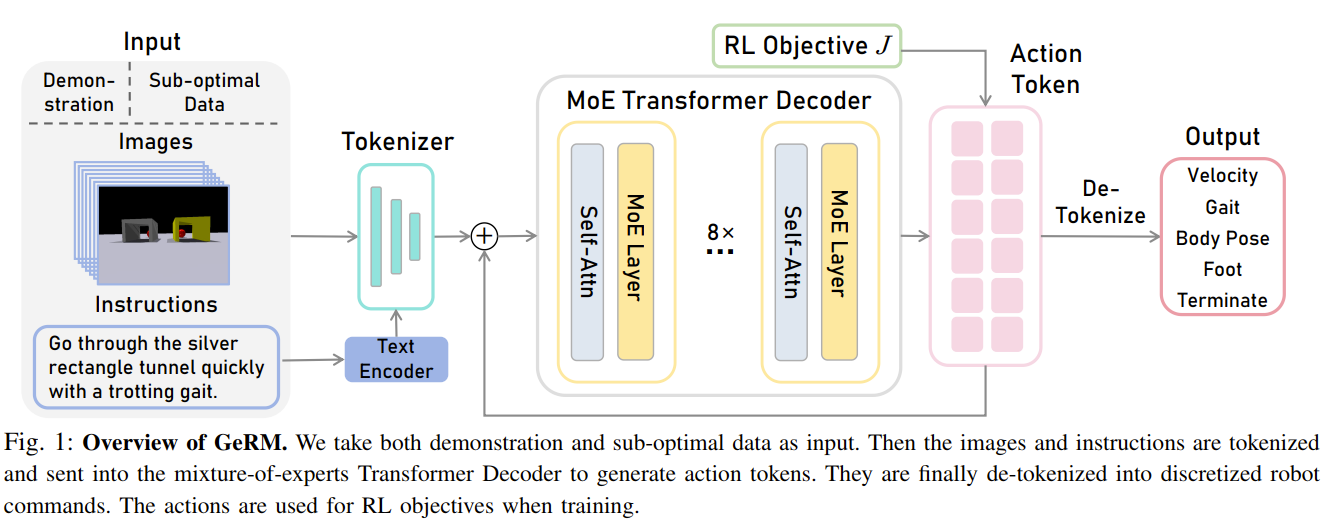
指明了具身智能的Scaling路径: 它证明了MoE是实现 “大模型(高容量)+ 高效率(低推理成本)” 的有效途径。这为构建更大、更通用的机器人模型(就像LLM从Dense转向MoE一样)提供了范例。
PS:虽然MoE看多了感觉挺没新意的,但是或许它来做scaling确实很有效!
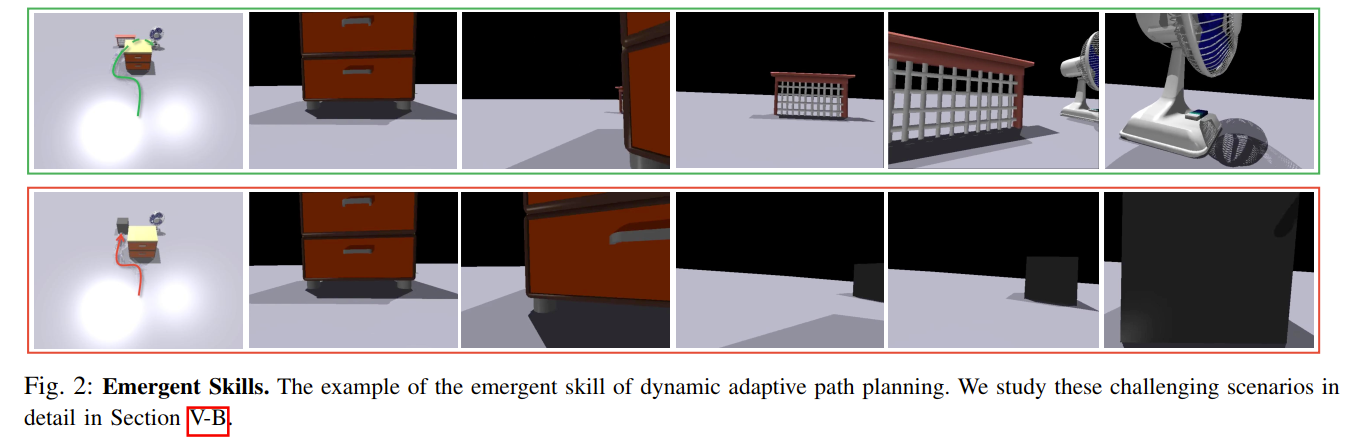
论文还展示了涌现能力 (Emergent Skills) (Fig. 2) ,例如动态自适应路径规划:机器人在视野受限时,会先转弯探索,发现走错后能自主纠正并重新规划路径。
我的评分: ⭐
VLA-RFT
我的评价:验证性奖励机制设计的不赖。
关键信息
动机是寻找一条兼顾效率、安全与性能的VLA模型增强路径。
不同点:与依赖离线RL(如ARFM)、在线RL(如VLA-RL)或传统模拟器RL的前沿工作不同,VLA-RFT的核心创新在于使用一个数据驱动的世界模型 (Data-driven World Model) 作为策略优化的“沙盒”。
设计了“验证式奖励”(Verified Reward)机制:这是该框架能成功的关键技术。它不直接比较世界模型生成的图像与真实图像(这会受到生成质量不完美的影响),而是在世界模型内部进行比较:将“策略产生的动作”和“专家演示的动作”分别输入到 同一个世界模型 中生成两条“想象”的轨迹,再计算这两条轨迹的相似度作为奖励。这种“在想象中对比想象”的思路,巧妙地抵消了世界模型自身的生成偏差,提供了一个更稳定、可靠的优化信号。

该图展示经过第二阶段的RL训练动作分布更加丰富。
Method
寻常VLA,自回归World Model,第一阶段VLA和World Model预训练,World Model 最大似然loss训练。
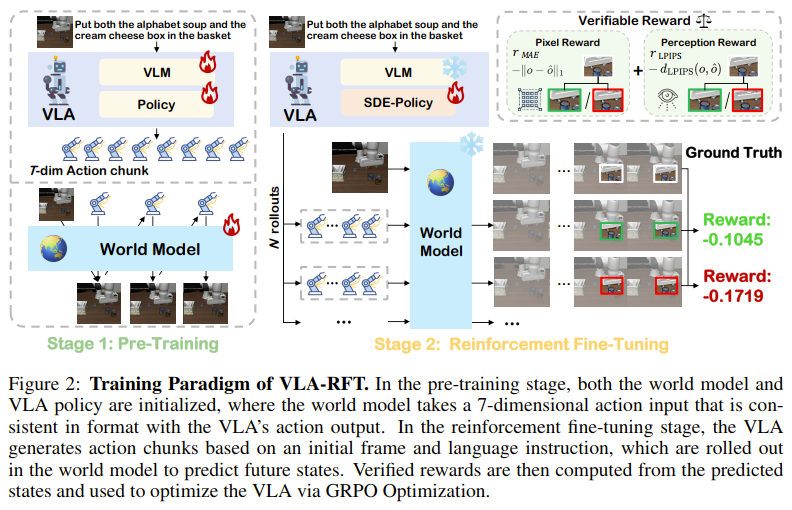
第二阶段
VLM和WM冻结。有关Policy:
-
他们额外增加了一个小网络,叫做 Sigma Net(Eq. 7)。
-
现在,当策略决定一个动作时,它会做两件事:
- Flow-Matching 头(
μ_k ) 预测一个“它认为最好的”确定性动作(就像以前一样) (Eq. 5)。 - Sigma Net(
Σ_k ) 预测一个“不确定性范围”(即方差)。
- Flow-Matching 头(
奖励 R 是一个负数(即成本/惩罚) ,由两部分组成:
-
L1(像素损失):两个视频的像素差异有多大? -
LPIPS(感知损失):两个视频在“人眼看起来”的相似度有多大?(这个更重要,它不要求像素完全一致,只要“看起来差不多”就行)。
循环取平均计算优势,减小方差。
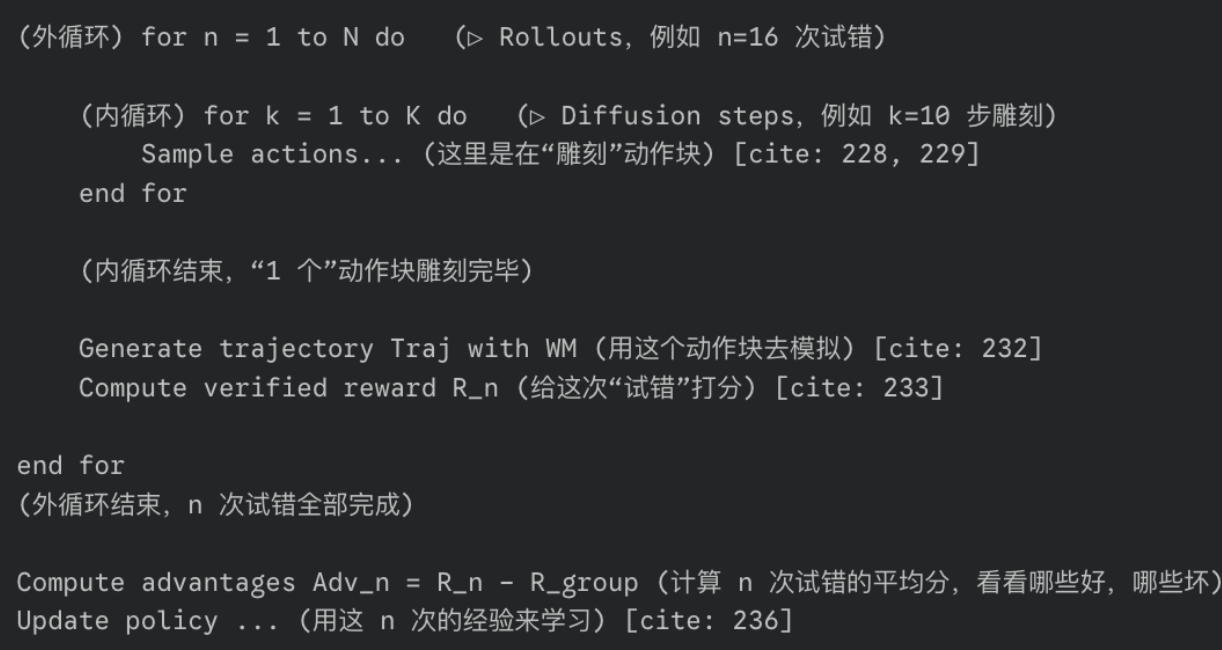
Insight
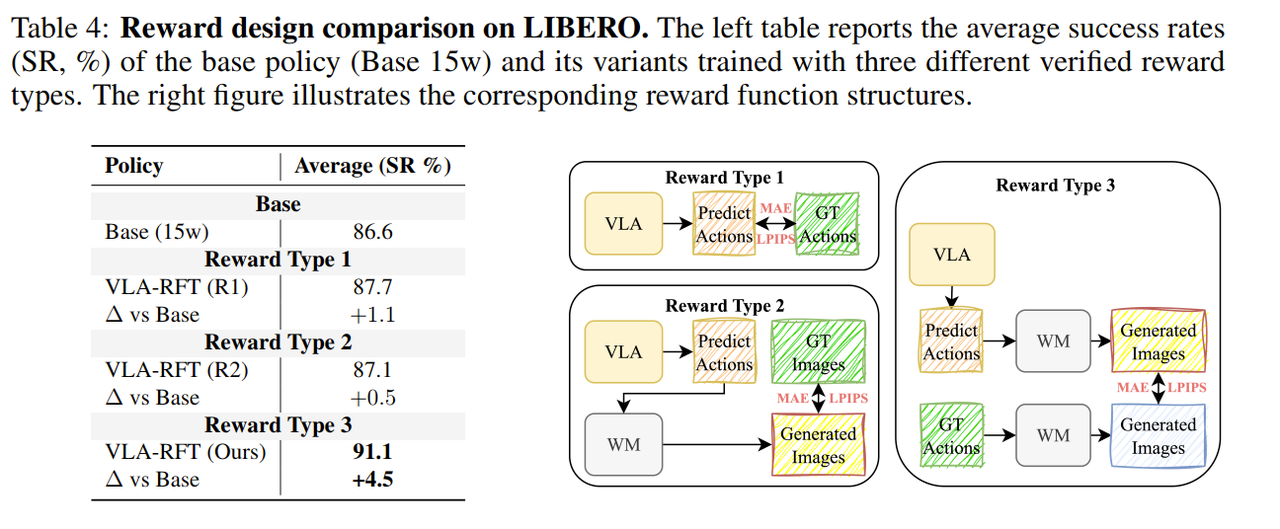
抵消世界模型自身偏差是有效的!
策略仍然受到专家数据集质量的制约,这限制了其发现超越专家表现的策略的能力。其次,WM 的表征能力构成了一个瓶颈。当前的框架没有将 WM 显式地集成到“规划”(planning)中,而这本可以进一步增强长时序推理能力。第三,可验证奖励机制本身也可以被改进:未来的工作可以利用学习到的奖励模型[6]。最后,虽然研究集中在基于流匹配(flow-matching)的策略上,该框架扩展以包含更广泛的策略架构仍然是未来研究的一个重要方向。
我的评分:⭐⭐
VLAC
AILab网红工作,温故一下。
我的评价: 通用奖励预测模型,基础扎实。
Method
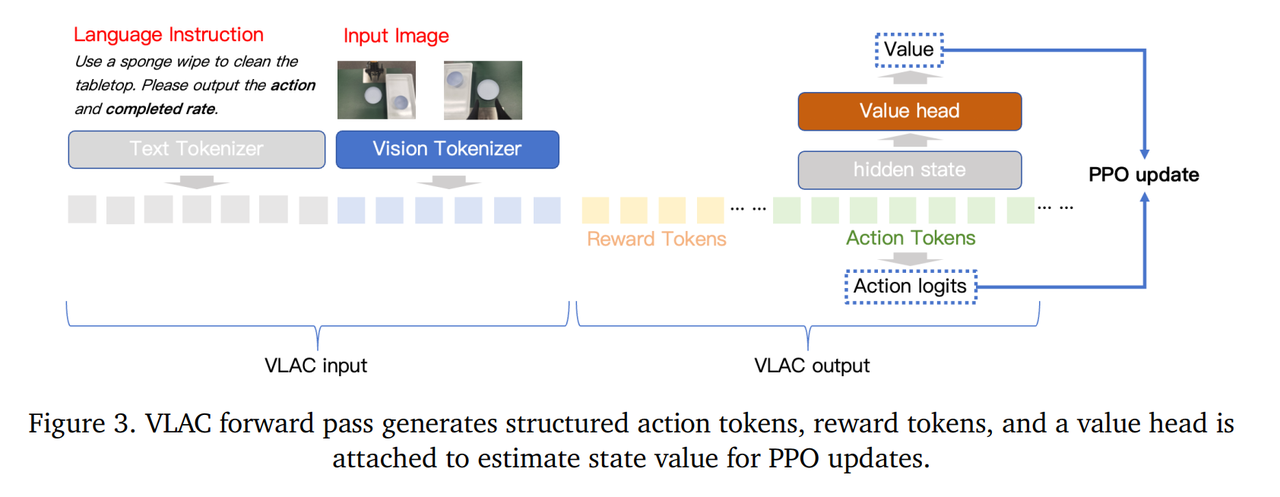
8B VLAC 2BVLAC是两个架构一样的独立的网络。
第一阶段预训练 第二阶段真实世界强化学习。
一个8B VLAC先在离线数据集自给自足地进行PPO训练,第二阶段被冻结只使用critic部分。
一个2B VLAC同样先在离线数据集上独立地自给自足地进行PPO训练,第二阶段只用actor部分会被进一步训练。
Actor-Critic的异步:
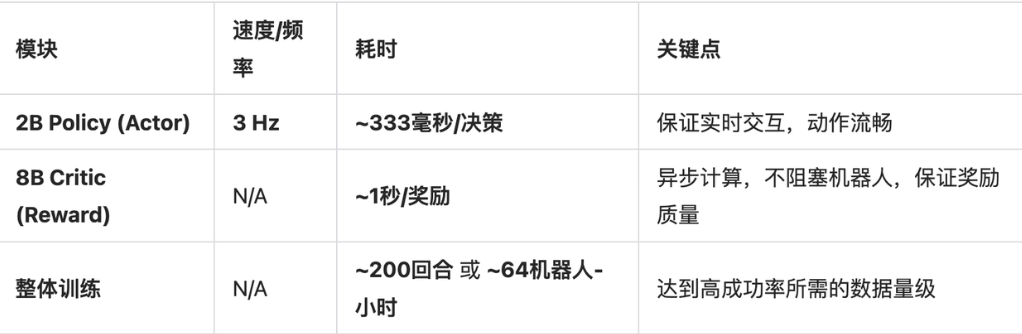
64个机器人小时 –> 8个机器人并行训练8个小时。
有关在线强化学习:异步Actor-Critic,分policy actor和learner actor,每一个固定的训练步数周期,后台缓存数据,缓存的足够多了更新一次权重。
Insight
当前的 RL 框架(PPO + 自回归 tokenized 动作)与 VLAC 特定的离散语义动作头“紧密耦合” (tightly coupled) 。这套方法无法“直接推广” (directly generalize) 到其他类型的动作解码器,例如扩散 (diffusion) 或流匹配 (flow-matching) 模型 。
当尝试同时对多个任务进行在线 RL 训练时,模型表现出 “奖励尺度漂移” (reward scale drift)、“任务间梯度干扰” (inter-task gradient interference) 和“情景遗忘” (episodic forgetting) 。论文承认,目前尚未集成必要的稳定性机制(如任务自适应归一化、梯度冲突缓解等) 。
Core Insight:
- 非对称 Actor-Critic 架构:解耦“理解”与“行动”:“重理解、轻行动”的解耦是实现低延迟和高效实机(real-world)RL 的关键工程实践。
- 将“进展”本身建模为通用奖励 (Modeling “Progress” as a General Reward):它利用了海量的、异构的数据集,包括不带动作标签的人类视频(如 Ego4D) 。这意味着模型可以从海量的人类活动视频中学到“什么是进展”的通用概念,然后将这种理解能力迁移到机器人上,作为密集的 RL 奖励信号,从而“消除了针对特定任务的奖励工程”。
- 务实的人在环路 (HITL) 策略 (Pragmatic Human-in-the-Loop Strategy):“离线演示回放” (Offline Demonstration Replay) 、“返回并探索” (Return and Explore) 和“人工引导探索” (Human Guided Explore)。
我的评分:⭐⭐⭐⭐
RL100
许老师网红工作,温故一下。
我的评价: 能做出这种工作的人,一定有丰富的经验,对人工智能未来的发展以及AGI的最终形态有深度思考。
关键信息
RL-100 引入了一个三阶段流程。
- 首先,通过模仿学习利用人类先验知识。
- 其次,迭代式离线强化学习使用离线策略评估(OPE)程序,来门控(gate)应用于去噪过程的 PPO 风格更新,以实现保守且可靠的性能提升。
- 第三,在线强化学习消除残留的失败模式。 一个额外的轻量级一致性蒸馏(consistency distillation)头将扩散模型的多步采样过程压缩为单步策略,在保持任务性能的同时,将延迟降低一个数量级,从而实现高频控制。
该框架与任务、机器人形态(embodiment)和表征无关,支持 3D 点云和 2D RGB 输入、多种机器人平台以及单步和动作块(action-chunk)策略。
这些结果表明,通过从人类先验出发,将训练目标与人类认可的指标对齐,并可靠地将性能扩展到超越人类演示的水平,是实现“可部署级”机器人学习的一条切实可行的路径。
许多模仿学习策略(如DP)能达到 70%-80% 的成功率,但在真实世界中“几乎”成功等于失败。这篇论文的核心是解决如何弥合 “模仿天花板” (imitation ceiling) 与 100% 完美执行之间的差距。RL-100 的核心创新在于“后训练” (post-training),通过后续的离线和在线 RL 阶段。
全真机。
DSRL / DPPO 等“扩散+RL”算法:
- 延迟 --> 一致性蒸馏 (Consistency Distillation)
- 稳定性 --> OPE 门控的迭代式离线 RL
RL相关:
- 离线和在线阶段统一使用 PPO 风格的策略梯度目标, 直接优化扩散模型的去噪子步骤 ,这保证了阶段间的稳定过渡和样本效率。
- 一个自监督的视觉编码器 ,该编码器在 RL 探索和更新期间能提供稳定且抗漂移的视觉表征。
对重置 (Reset) 的依赖: 需要人工干预来重置环境。作者承认 “重置和恢复仍然是实际的瓶颈” ,并将其作为未来工作 。未来工作中也提到,需要扩展到更复杂、混乱和部分可观测的真实家庭或工厂环境。
Method
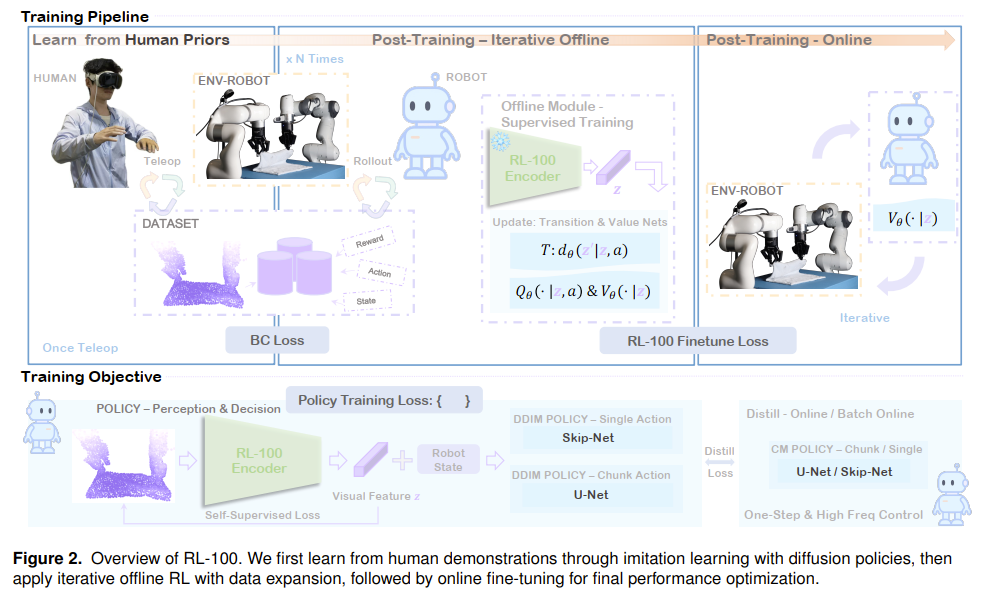
(1)从人类演示中进行模仿学习,(2)通过渐进式数据扩展进行迭代式离线 RL,以及(3)在线微调。关键的创新在于,通过一个共享的、应用于扩散去噪步骤的 PPO 风格目标函数,来统一离线和在线 RL。
整个Method部分过于的Solid,与其我复述复述一遍,不如直接和Gemini老师去读一下原论文Method这一段。由于我读到这里脑袋有点累了,直接打草稿放飞自我了。以下是我的草稿:

Joint Training全程蒸馏这个思路确实很惊艳。
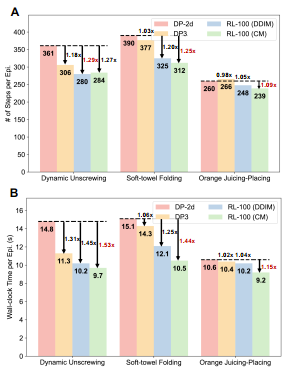

超越人类摇操数据以及一致性蒸馏带来的效率提升。
Insight
- 设计一个更鲁棒的、能不断消除Failure Mode的“训练-验证”系统。
- “超越人类”的范式得到了验证。人类的角色正在从“策略的提供者”转变为 “价值(奖励)的定义者”和“系统的引导者” 。
- 在真实世界中,RL 算法的“保守性”和“稳定性”比“样本效率”更重要。
- “训练模型”与“部署模型”的彻底解耦。启发我们训练时的计算瓶颈(高延迟、大模型)在部署时可能根本不是问题。我们可以放心地使用极其强大的(但很慢的)模型作为“教师”来探索和学习,只要我们能把它的能力蒸馏到一个轻量、快速的“学生”模型上即可。
我的评分:⭐⭐⭐⭐
VITA-VLA
南大高阳老师的工作。
我的评价: 这方法的“脖子”很粗,没有可解释性。思路还行,对齐做的不错。
关键信息
动机非常明确和务实——降低成本、提升效率。从零开始训练一个大型VLA模型需要海量的数据和算力,而现有的大模型在机器人任务上表现又不如专门的小模型。因此,作者希望找到一种“捷径”,将小模型的“动作技能”高效地“注入”到大模型的“大脑”中,实现“1+1>2”的效果。
它不是简单地让大模型模仿小模型的最终动作输出,而是通过一个创新的对齐阶段(Alignment Stage) ,在隐藏空间层面将VLM的表征与小模型的动作表征对齐。这使得VLM能够理解并生成与小模型动作解码器兼容的“指令”,极大地提升了知识迁移的效率和效果,避免了昂贵的从零训练。
全文实验对比的动作专家Baseline 是 Seer。
Method
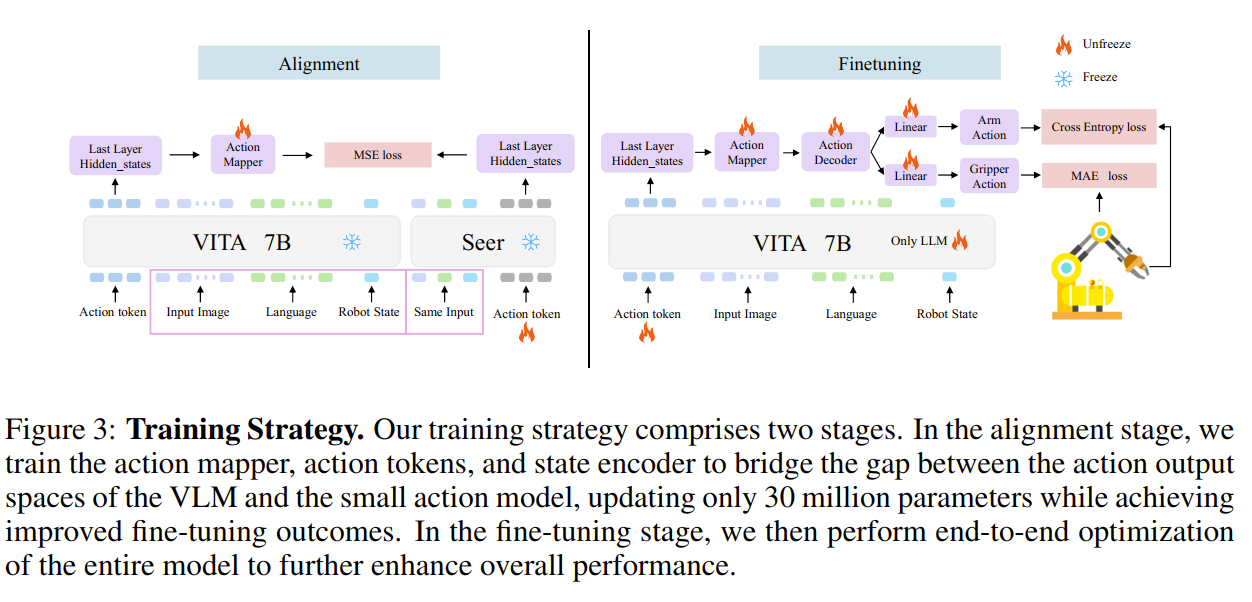
第一阶段是蒸馏,把Seer的知识蒸馏到Action Mapper(MLP)里面。可以理解为一个很聪明的MLP初始化方法。

我的评分: ⭐⭐
RLVR-World:Training World Models with RL
来自清华软院和清华一所响应“强基计划”建立的学院
我的评价:方法不错,实验做的很好很有说服力。
关键信息
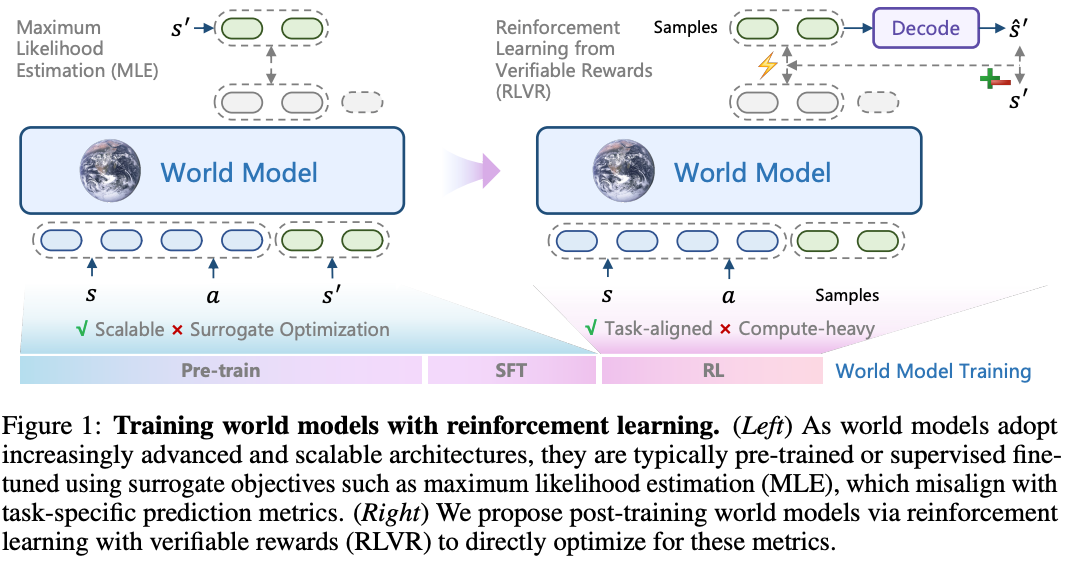
主要解决世界模型训练中的 “目标不对齐”(Objective Mismatch) 问题。传统训练方法(如MLE)优化的是“下一步预测的概率”,但这不等于 “长期、高质量、符合人类感知的预测” 。
先用MLE进行预训练,然后用RL进行后训练,直接优化那些对任务真正重要的、甚至是不可微分的指标(如F1分数、LPIPS感知损失)。
作者观察到,在LLM的数学和代码生成任务中,RLVR取得了巨大成功。他们认为,世界模型的“预测准确性”本身就是一种理想的、可验证的奖励信号。因此,核心动机是将LLM领域的成功训练范式迁移并泛化到更广泛的世界模型(包括语言和视觉)中,以解决长期存在的训练目标与最终性能不一致的问题。
提出一个统一框架,将不同模态(语言、视频)的世界模型训练范式化。这是一个具有高度通用性和扩展性的训练思想。
拓展了语言世界模型的实验,在复杂的动态世界状态预测任务(如文本游戏、网页DOM变化)中表现出色。(这个实验说服力倒不错)
Method
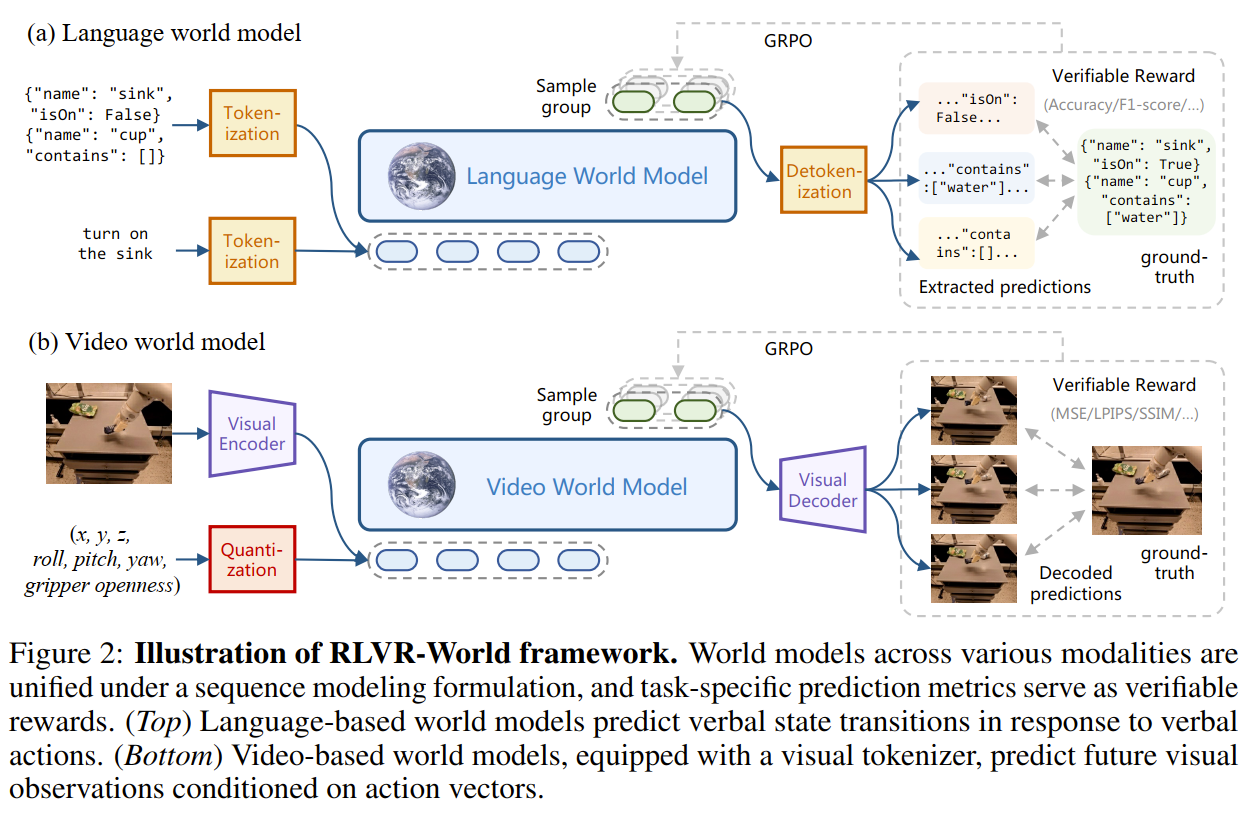
万物tokenize的思想,Visual Encoder其实是一个VQ-VAE/VAGAN,先编码后量化然后输出离散的token序列。对于像机器人本体感知信号(如关节角度)这样的低维连续数据,将其量化 (quantized) 到一个固定范围内的均匀“桶” (uniform bins) 中。

“可验证奖励”


实验&&Insight
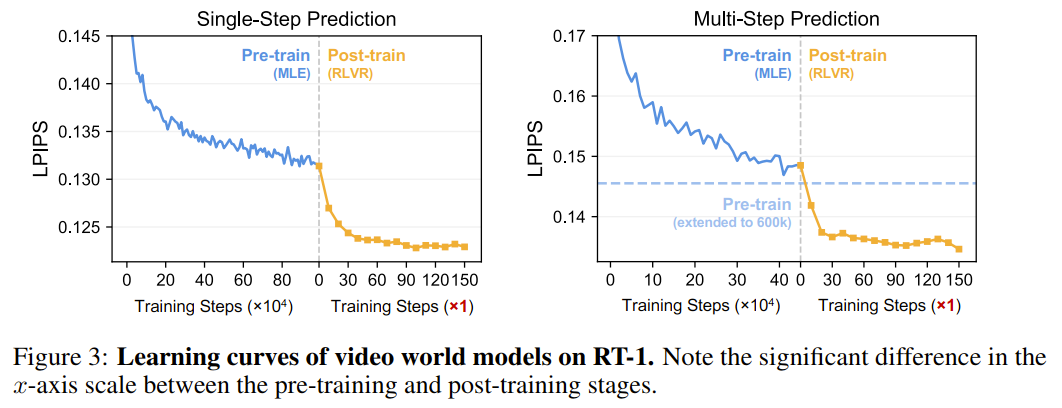
恐怖的效率。
-
缓解重复性
- 最大似然是重复的主要原因,LLM和视频预测中均发现这种现象。
- 大约 20% 的帧内 token 与前一帧相比是保持不变的。这导致了模型(在MLE训练时)学会了走“捷径”:即通过“重复”来优化其“下一个token”的预测似然。
- RLVR-World 通过直接优化视频级的预测指标(如LPIPS),而不是优化“下一个token”的似然,从而有效缓解了这个问题。这种方法使视频的重复率从 48.6% 骤降至 9.9% 。
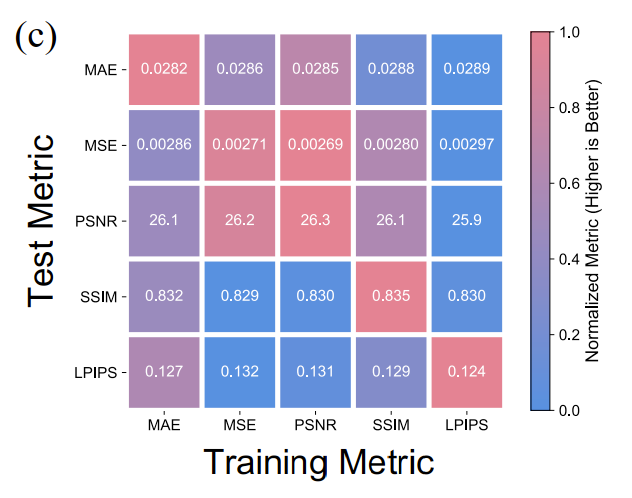
-
指标导向性优化(如上图)
- 用 LPIPS 作为奖励训练的模型,在 LPIPS 测试指标上表现最好。用 MSE 作为奖励训练的模型,在 MSE 测试指标上表现最好 。
- 额外验证 (非微分奖励): 作者还引入了一个“重复惩罚奖励”(即“连续相同帧”的负比率),以展示该方法对非微分奖励 (non-differentiable rewards) 的有效性。结果(见 Table 3)表明,模型在保持同等预测性能的同时,完全消除 (eliminate) 了重复伪影。
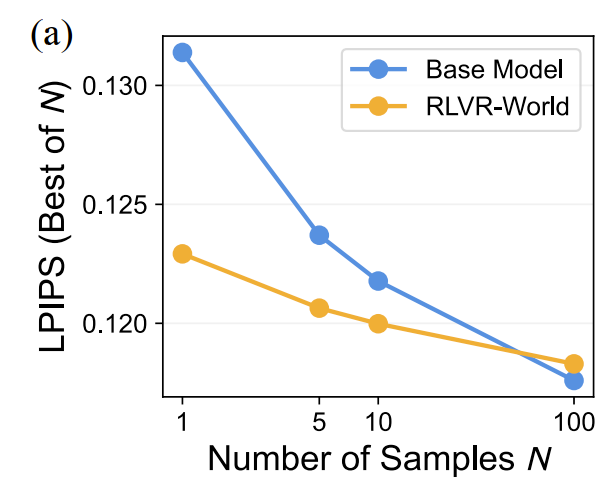
-
Test-time scaling
- 在测试(推理)时,如果生成 个样本,然后从中选出“最好的”一个,性能会如何变化 ?
- N 较小时 (N=1): RLVR-World 的 “单次” (one-shot) 性能远超基础模型 。它的 N=1 表现甚至优于基础模型的 N=5 表现 。这在计算资源有限的实际场景中非常有价值。
- N 较大时 (N=100): 基础模型 (Base model) 的性能最终追上并超过了 RLVR-World 训练的模型。
- 结论: 这揭示了当前 RLVR 方法的一个局限性 。RLVR 似乎使模型“收敛”到了一个高质量的单一模式,而基础的 MLE 模型可能保留了更大的“多样性”(即使很多样本质量不高)。这也为未来的研究提供了机会
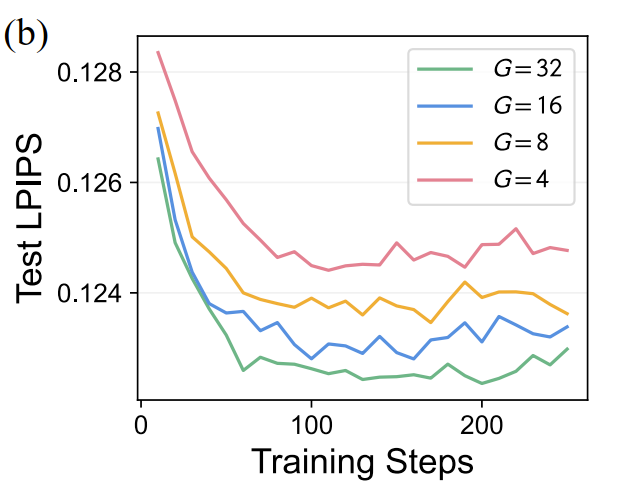
-
GRPO RL Training Scaling
- 增加 (例如从 增加到 )可以提高收敛速度和最终性能(更低的 LPIPS)
- 这是因为在训练时生成更多的样本(更大的 )可以增强样本多样性 (sample diversity) 并扩大探索空间 (exploration space) ,从而帮助 RL 算法更好地进行优化。
RLVR 弥合了(MLE)预训练目标与(LPIPS 等)视觉预测指标之间的差距,从而带来了更准确的预测、更高的训练效率,并减少了(如“重复”)等伪影。
我的评分: ⭐⭐⭐
Data-Efficient RLVR via Off-Policy Influence Guidance
清华大学唐杰教授团队,10%数据反超全量训练!不过该工作是针对LLM的。
我的评价: 挑选数据的动态课程学习框架很有意思!
关键信息
在使用可验证奖励的强化学习(RLVR)来增强大型语言模型(LLM)推理能力的过程中,数据选择是一个关键方面。本工作提出了一种理论上更完备的方法,使用影响函数(influence functions)来估计每个数据点对学习目标的贡献。为了克服在线影响估计所需的(高昂计算成本的)策略 rollout,我们引入了一种**离策略(off-policy)影响估计方法,它使用预先收集的离线轨迹来高效地近似数据的影响力。此外,为了管理LLM的高维梯度,我们采用稀疏随机投影(sparse random projection)来降低维度**,并提高存储和计算效率。
利用这些技术,我们开发了 CROPI(Curriculum RL with Off-Policy Influence guidance) ,一个多阶段RL框架,它迭代地为当前策略选择最有影响力的数据。
实现了2.66倍的步数级加速 。
结果凸显了基于影响的数据选择(influence-based data selection)在高效RLVR中的巨大潜力 。
核心动机是 “如何在计算成本可控的前提下,将影响函数的理论优势引入到RLVR的数据选择中?”
Method
为什么 Off-Policy Gradient可行?
在RLVR(如GRPO算法)的训练中,通常会有一个 KL 散度约束,使得当前策略 不会偏离初始策略 太远。因为 和 始终保持“相对接近”,所以用 的轨迹来估算 的梯度是“相对准确的” (relatively accurate)。
稀疏随机投影 (Sparse Random Projection)(其实相当于梯度的"Dropout")
LLM的梯度维度极高(),直接存储和计算(如计算内积)的成本高到无法接受。因此必须进行降维,但降维需要保持梯度间的相似度排名(即“秩保持”,Rank Preservation)。为什么丢弃信息反而效果更好?作者推测这与数值噪声 (numerical noise) 有关 。而稀疏化(Sparsity)虽然屏蔽了部分信息,但也恰好过滤掉了大部分噪声,从而在稀疏率为 0.1 左右时达到了最佳的“信噪比” (signal-to-noise ratio) 。
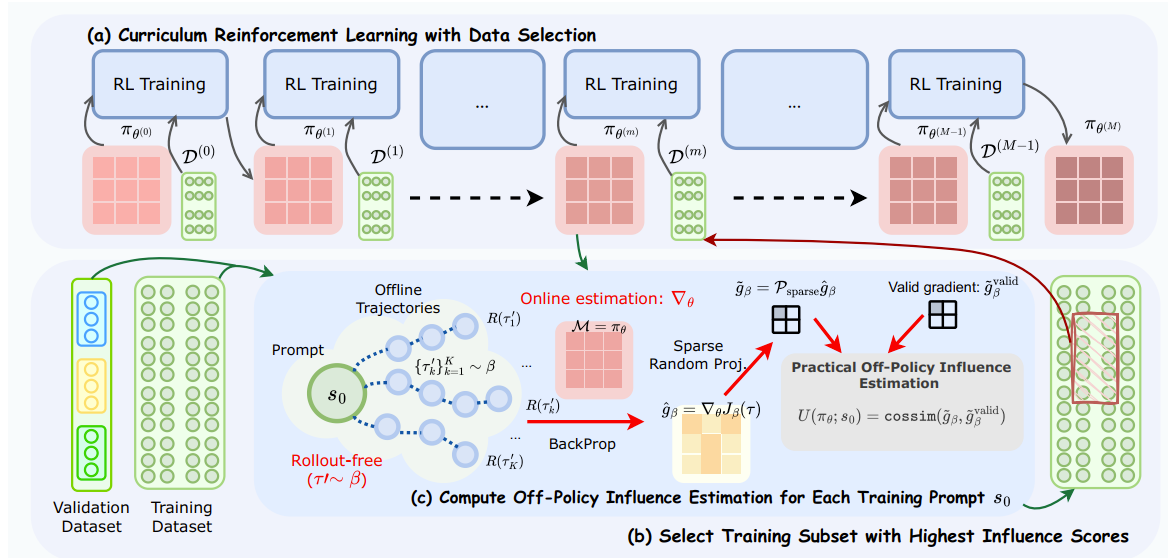
如何计算一个数据对单个验证级的影响力?
- 首先,计算整个验证集 的平均梯度特征 。这代表了“提升验证集整体性能”所需要的目标梯度方向。
- 然后,一个训练数据 的 POPI 影响力分数被定义为: 的梯度特征 与验证集平均梯度特征 之间的余弦相似度 (cossim) 。
融合多个验证集给数据点打分。
- 计算 在每个验证集 上的 POPI 分数排名 。
- 根据公式 (7),将每个排名的倒数 相加,得到最终的 RRF 融合分数 。
- 直观理解: 一个数据点如果在多个验证集上的排名都很高(即 很小),它的总分 就会很高。
每一个阶段用排名前10%的数据。
“CROPI 到底选了什么样的数据?”
-
分析 1:语义相关性 (Semantic Correlation) (见 图5)
- 这证明了 POPI(本文提出的影响力估计器)虽然是基于梯度空间计算的,但它能有效地自动识别出在语义空间上与目标最相关的数据
-
分析 2:通过率 (Pass Rate) (见 图6) 这是本节最关键的洞察,它揭示了 CROPI 的动态课程学习特性
- 随着模型变强,CROPI 会动态选择对“初始模型”来说越来越难的数据。
- 这说明虽然选出的问题越来越难,但它们恰好是“当前模型”有能力学会的 。
我的评分: ⭐⭐⭐
小结&&Little Talking
读完这些论文,我看到了一个后训练时代。《The Bitter Lesson》的幽灵贯穿始终——我们正从依赖人类知识(如BC所需的高质量专家数据 )转向更充分利用算力(如RL的自我探索和优化)的通用方法。这次调研的所有工作,几乎都是在回答这个核心问题:我们如何构建一个能自我改进的 “数据飞轮” ?
-
飞轮在哪里转?
- 真实世界 – PAC PLD RL100
- 想象世界 – WMPO VLA-RFT
-
Reward从哪里来?
- 自预测奖励 – Self-Improving EFM VLAC
- 验证式奖励 – VLA-RFT RLVR-World
- 曲线救国 – ReinboT
-
Scaling靠什么?
- 架构迁移 – PAC的Perceiver Q-Transformer MORE GeRM (明确使用MoE来平衡容量和效率)以及MuYao老师最近的AdaMoE[7]。
- 范式迁移 – “Pre-train (BC/MLE) -> Post-train (RL)” 正在成为标准。PAC的 超参提供了从BC到RL的平滑过渡;RL100 的三阶段流程是这一范式的完美体现;RLVR-World 更是将其形式化为 (MLE Pre-train -> RL Post-train)。
-
“燃料”怎么选?
- Data-Efficient RLVR 这篇工作,虽然针对LLM ,但它完美地回答了:如何为“数据飞轮”提供最高效的“燃料”?– 一个全自动的“因材施教”的动态数据选择系统 。
“想象”的路线追求的是极致的样本效率,“实践”的路线更贵、更慢,追求稳定性。
RL100 和 VLAC 所展示的“非对称/解耦”架构(如重Critic/轻Actor ,或重Teacher/轻Student )可能是短期的最优解。它允许我们在训练时(无论是在“想象”还是“真实”中)使用极其强大的(但很慢的)模型去探索,然后将能力蒸馏到一个轻量的、可部署的模型上。
这是我的第一篇公开blog,我要说的大概就这些,我没法靠读Paper思考出太多东西。之后在实践过程中有所感悟会及时分享!
References
[1] RL100
[2] LocoFormer
[4] Training Compute-Optimal Large Language Models
[5] How Do VLAs Effectively Inherit from VLMs?
[6] VLAC
[7] AdaMoE-VLA




